Final Report on CCG Generalization
ARL Contract
TelArt Inc., Chantilly Virginia
December 31, 2000
Dr. Paul S. Prueitt
![]()
Preface
In May 2000, Zenkin and Prueitt
discussed the possibility that there might be a common scheme in the use to CCG
technology in new knowledge generation. This discussion occurred after Dr.
Prueitt had developed an appreciation of the Computer Cognitive Graphics
(CCG) technology as it is applied to number theory. Drs Art Murray, Alex
Citkin, Peter Kugler, Bob Shaw, Michael Turvey, and Kevin Johnson have assisted
him in this evaluation. Our first
project report to the ARL delineates this understanding.
Our final report to ARL generalizes
the CCG technology. From the generalized CCG it becomes clear that the
re-application of the original CCG technology to other objects of investigation
can be achieved if and only if all real aspects of the syntactic and semantic
representational problems are addressed.
The claim made in this ARL Report is
that the CCG technology, as applied to number theory, has addressed all real
aspects of the syntactic and semantic representational problems. A specific
object of investigation, this being the theorems of classical number theory,
shapes how these aspects are addressed. No semantic issues exist, except as
noted in the problem of induction. Thus the mass of the CCG technology is
merely formal and syntactic. The core, however, is essential and this core is
about how one manages mental induction.
We hold that induction is not and
cannot be considered algorithmic in nature. We cite Western Scholarship Robert
Rosen and Roger Penrose work as well as the work of J. J. Gibson and Karl
Pribram. Thus the interface between
algorithm computers and human mental activity is necessary in any generation of
new knowledge. It appears that much of
Russian Applied Semiotics is based on this Peircean concept that an
interpretant is actually required during the generation of new knowledge.
Section 1: A review of the CCG
application to number theory and its generalization
Specifically, elementary number
theory is a formal construct that is built on the Peano axiom, the additive and
multiplicative operators, and on the use of a principle of mathematical
induction. The CCG technology can then be seen to have the following parts:
A
representational schema
A
visualization schema
An
induction schema
In number theory, the representation
allows color codes to represent division properties. In classical number
theory, division does not induce non-integers, but rather truth evaluation of
whether a remainder is zero, (or any other integer - depending on the way the theorem
is stated). Now it is important to state that Dr. Prueitt has some background
in number theory and as a consequence of seeing number theory in a new light,
there appears to be new theorems regarding invariances of residues. Perhaps
others can see these new theorems also. There is additional work that would
have to be achieved in order to tease a the specific statement about these
theorems.
The possibility of new mathematics
is pointed out only because there is a mental effort required to think about
how color representation fits into the CCG methodology. That this effort has
lead to an intuition about new mathematics is a statement that must be taken on
a plausibility argument. This plausibility is ultimately how the CCG
methodology should be judged. Although
positive results of various types exist and can be shown, the conceptual
grounding for CCG remains foreign, not only due to Russian origin but primarily
due to the misrepresentations made by modern Artificial Intelligence regarding
the nature of human induction.
There is a suggestion that there are
some new theorems that are delineated by Prueitt's mental intuition when the
cognitive effort is made to describe the CCG techniques. Prueitt is willing to discuss this issue at
the proper time. However, the existence
of new theorems in number theory is not of immediate interest. Prueitt claims that the theory of algebraic
residues is not completely developed, and that pure mathematicians who know
this field well will be able to quickly see the same intuition. This intuition comes immediately from the
realization of how color-coding is used in the CCG applied to number theory.
How would CCG assist in our
experiencing intuitions?
An induction is to be established by
the physical representation (by colors in this case) and the subsequent
representation of truth/falseness evaluation of specific properties of a
generated sequence of numbers using the 2 dimensional grid. Zenkin has many
examples of how this has worked for him. Prueitt sees a different class of
theorems because he has a different mathematical training and internal percepts
about the Peano axiom and the additive and multiplicative operators. Any other
pure mathematician would see theorems that are new, depending on the nature of
the intuitions that are resident in the mind of the pure mathematician. CCG would be useful in the completion of
mathematical reasoning from whatever experience the mathematician might have.
Prueitt holds that any formal system
can be vetted using slight modifications of the CCG representation and
visualization demonstrated by Zenkin. If this claim is correct, then areas of
abstract algebra would fall under the technique. The requirement is that a
human has deep intuitions about an object of investigation and that the
representation and visualization setup a route to induction regarding truth /
falseness of theorems (see the work of Russian father of quasi axiomatic
theory, Victor Finn, on routs to induction).
This means that someone who is
deeply involved with algebra and who studied the CCG applications to number
theory would likely begin to (immediately) see how to represent and visualize
relationships such as the property of being a generator of a semi group. Once
this new mental intuition is established, then a principle of induction is
required that allows the validation, or falsification, of intuitions. In the
past application of CCG to number theory, this validation of intuition is
equivalent to a formal proof, and yet is made using a proxy that is visual in
nature. The proxy is established via the notion of a super-induction
where the visual observation of a property transfers to a formal declaration of
fact. This transfer is the core of the CCG technology and is not dependent on
the specific representation or the visualization, as long as the visualization
schema matches (completely) all syntactic and semantic representational
problems.
In formal systems, the problem of
syntactic and semantic representation is not only simple; but is also complete.
There is little or no semantic dimension. Only the truth evaluation is semantic
and this semantic evaluation is incompletely represented in the iterated
folding of syntactic structure (via rules of deductive inference). In essence,
one can almost claim that the only semantic aspect about number theory is that
someone who sees the elegance of it can experience it as beautiful. The caveat
is captured by the Godel theories on completeness and consistency, and on
related notions communicated by Cantor and others (including Robert Rosen’s
work on category theory). Of course, Zenkin is one of those who have advanced a
disproof of Cantor's argument regarding the categorical non-correspondence
between the whole numbers and the real numbers.
Prueitt reads this disproof in a
certain way. The argument that Canton's diagonalization theory is flawed is
really a comment on the nature of common mathematical induction. As Kevin
Johnson has pointed out, there are many many ways to perform an induction. The
common mathematical induction simply depends on an ordering of theorems in such
a way that the tail of this sequence of theorems has invariance with respect to
the truth evaluation. The CCG
representation and visualization simply allows a pure mathematician a by-pass
of all orderings except one that results in visualization of the targeted
invariance of a tail of a sequence of theorems. This by-pass is non-algorithmic and thus must be managed by a
human.
One can see this as a search space
problem. In many cases modern computer science has identified what are called
NP-complete problems. The NP-complete problem can be proved not to be
computably solved with the iterative application of the folding (application)
of the fundamental axioms and properties in the set up of the formal system.
However, visual acuity by a human might see a route to a solution. In fact,
Prueitt has made the argument that biological systems have evolved in such a
way as to by-pass NP complete problems. He claims that the capacity for seeing
a solution that cannot be computed is fundamental to biological intelligence.
In formal systems, the by-pass is
simply a lifting away from and a replacement into the formal construct. This
there is still no semantic dimension to the solution. This concept of lifting
is consistent with Brower’s notion of intuition (Bob Shaw – private
communication). This means that the
solution, once found, to NP-complete problems can then be proved using common
inference and common induction. It is just a question of skipping and
reordering.
Possible application to EEG and
stock market data analysis
Zenkin and Prueitt were hoping that
EEG data could be easily found with expert opinions about differential meaning
of data patterns in context. Due to the uncertainty of how we might precede
Prueitt did not pursue a collaborative relationship with EEG experts in Karl
Pribram's lab or in any other lab. Such collaboration requires that the method
we have devised for visualization be well developed and that our collaborative
project with the Russians be well funded.
As we worked on this issue, it
became clear that we could describe such a method only if the communication
between Russia and the United States was better. We need to involve neuroscientists both in St. Petersburg (Juri
Kropotov) and in the USA (Karl Pribram).
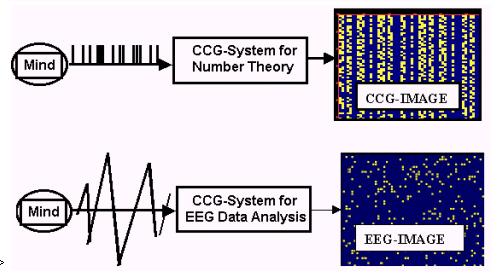
Given our limited resources, Prueitt
decided to attempt to generalize the CCG methodology and then project this
generalization back onto some object of investigation. The idea was that the
generalization and separation of parts of the CCG techniques would show us how
to proceed.
What we needed to figure out first
was how to characterize the CCG method in such a way that aspects of the method
could be separated into functional parts. Then each part might be generalized
and then projected into a new use case.
We were open to possible investment
directed at using indices in the analysis of stock market performance. This
possibility still exists. However, it is felt that this application is unwise
and not directed at a scientific or mathematical objective.
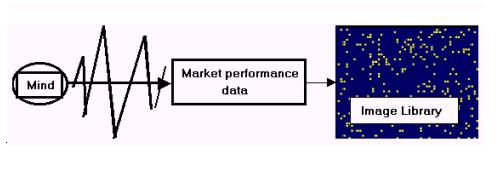
However, our thinking about the
markets allowed us to see, for the first time, that we needed to have an Image
Library. We needed a repository for the consequences of the evocation of
knowledge about, or an intuition about, the past or future performance of the
market. At this point, the work of other Russian applied semioticians (Pospelov
and Finn) come into play. The Library becomes a repository for a system of
tokens, each token deriving token meaning from intuitions vetted by the CCG
representation and visualization, and confirmed by an induction. The system is
then a formalism that is open to human manipulation as well as formal
computations. The formalism has both a first order and a second order (control
or tensor) system.
We have come face to face with the
core difference between a formal system, like number theory or algebra, and a
natural object of investigation, like the stock market. It is this difference
that is ignored by most Western mathematicians and computer scientists. It is
also this difference that illuminates the nature of Russian applied semiotics.
The case of this assertion will not be full made here; as to some extent the
assertion is ultimately a statement of belief.
In any case Zenkin and Prueitt both
agreed that an Image Library might be built as a type of Artifact Warehouse,
where the artifacts were the consequences of a super-induction
mediated by some representational and visualization schema.
The problems are then defined as
How does
one represent the object of investigation
How does
one visualize the accrual of invariance
How does
one establish conditions of induction
Prueitt has some experience with
scatter gather methods used in the standard methods for vectorization of text.
Thus he chose a collection of 312 Aesop fables to be his target of
investigation. This choice was a secondary choice, since TelArt Incorporated
continued to hope that situations in Russian might allow Alex Zenkin the time
required to make a paper on his own attempted application of CCG to scientific
data of some sort. As the deadline for our Final Report neared, it became clear
that Prueitt would have to write the Final Report without additional original
work from Russia.
In the next sections, results of the
generalization of CCG are applied to the problem of parsing text. Text parsing
ultimately is to be applied to a routing of information or a retrieval of
information. Prueitt is designing a system for a worldwide evaluating of
Indexing Routing and Retrieval (IRR) technologies, and thus the use of
Prueitt's background was capitalized on for the purpose of completing our
contractual obligations.
The URL announcing this IRR
evaluation is at: link
![]()
Section 2: The
Application of CCG generalization to the problem of text parsing
ARL has expressed an interest in text parsing. Thus it is important to specify how we see test parsing fitting into an architecture that deploys a generalization of Russian CCG technology.
The diagram for this architecture has the following parts:
1) a preprocessor for data streams
2) an image library
3) an visualization interface and control system
4) indexing engine,
5) routing and retrieval engines
6) a viewer or reader interface with feedback loop to 2, 3, 4 and 5
Component 6 is where we might have a decision support interface. Components 2, 3 , 4, and 5 are really the components of a knowledge warehouse. These components are built up over time. In the data mining terminology, component 1 is called a data-cleaning component.
The preprocessor simply must do what is necessary to put the incoming information into a regular data structure. The cleaned data structure can have many different types of forms, however in the text-parsing task all of these forms have deficits. Again, this is due to the indirect relationship that the textual information has to the experience of awareness or knowledge. We seek to transfer the interpretability of natural text into an image framework.
The viewer interface is used in real time on problems of some consequence. Thus there is a systems requirement that a feed forward loop be established from one decision-making event to the next. The feed forward loop must touch components 2, 3, 4 and 5.
This architecture allows at least three places where human perception can make differences in the systems computations. The first is in the development of the image library (perhaps a token library is a more general concept). The second is in the indexing of the library components and perhaps some data streams. The third is in the decision support system (component 6).
Section 2.1
In Section 1, we made several claims. One of these is that the flow of information from an object of investigation can be vetted by a human computer system if and only if all real aspects of the syntactic and semantic representational problems are addressed. The flow of information from an object of investigation is likely to suffer from the data source being somewhat indirect, as in EEG data and linguistic data. Data sources such as astronomic data are more direct and thus more like the formal data sources such as number theory.
The partial success of statistical methods on word frequencies attests to the fact that a partial solution to these problems leads to an imperfect result. The glass is either half empty or half full. We do not know how to make this judgment, because today there is no completely satisfactory automated text parsing system.
The indirect nature of the data source would seem to imply that a human interpretant is necessary before there can be really successful text parsing. Thus the notion of vetting is proper, since this notion implies causation on a process that is mediated by a knowledgeable source and human judgment. The goal of a CCG system for text parsing is to transfer the interpretive degrees of freedom of text into an image framework. Once in the framework certain algorithm paths can produce suggestive consequences in new context.
It is not yet known if new methodology, entirely separate from the existing routing and retrieval technologies, will give rise to new and more successful results. We have suggested that much of the statically work on word frequencies is hard limited by the nature of anticipation. The statistical sciences can tell perhaps everything about the past, but cannot always predict the future. Moreover, we have the problem of false sense making. The meaning of words is enabled with ambiguity just for the purpose of predicting the meaning of words in contexts that are bound in a perceptional loop. This loop involves both memory and anticipation.
One can revisit the TREC and TIPSTER literatures, as we at TelArt will be doing over the next three months. In this review, we find not only statistical approaches, such as those made by David Lewis at AT&T and Susan Dumas at BellCore, but also a few linguistic and semantic methods. These methods are being reviewed as part of the Indexing Routing and Retrieval (IRR) evaluation by conducted by TelArt for a commercial client.
An understanding of routing and retrieval techniques might assist the generalization of the CCG technology. This generalization was done to establish some broad principles that might be formative to a proper text parsing system. The CCG technology can then be seen to have the following parts:
1) A representational schema
2) A visualization schema
3) An induction schema
New thinking on indexing, sorting or arrangements of data atoms may also provide value to our task. As we look for tools and methods we will of course be somewhat hampered by the now proprietary nature of new technologies. However, this is just part of the task we set for ourselves.
The application of CCG technology to the problem of text parsing requires that our group have a command of all existing IRR technologies and theory.
![]()
Section 3: Strategy for
organizing text data using CCG plus other techniques
Computer Cognitive Graphics
(CCG) is a technique developed by Alexander Zenkin. The technique uses a transformation of sequence values into a
rectangular grid. Visual acuity is then used to identify theorems in the domain
of number theory.
Our purpose has been to
generalize this work and to integrate the components of CCG technique with
knowledge discovery methods more widely used for automating the discovery of
semantically rich interpretations of text.
An application of knowledge discovery
in text is underway. As a general
capability a parse of text is to be made in the context of a number of text
understanding tasks.
Test Corpus: We have
several test collections, however only one is non-proprietary. This corpus is a collection of 312 Aesop
Fables. We will demonstrate some
work on identification of the semantic linkages between the 312 elements of
this collection in the last section (section 4).
In a text parsing system, the
interpretation of text is oriented towards retrieval of similar text units,
the routing of text units into categories and the projection of inference about
the consequences of meaning.
As part of a commercial
activity, TelArt Inc. is developing behavioral criterion for commercial clients
regarding proper evaluation of text vectorization, Latent Semantic Indexing,
CCG – derived, and other informational indexing systems. Most of the direct work on criterion is
proprietary in nature. However, the
movement from one domain to another domain of interest will produce a variation
of behavioral criterion. Thus client
criterion can be generalized to fit many other domains outside the domain of
content evaluation. This moves us
towards the notion of ultrastructure as developed by Jeff long at the
Department of Energy.
Thus we envision the development
of generalized behavioral criterion for evaluation of Indexing Routing and
retrieval technologies. Behavioral
criterion for intelligence
vetting is an interest to TelArt Inc.
TelArt is, of course, interested
in a full-scale program involving principals at New Mexico State University and
universities in Russia on situational logics and text parsing systems.
Use case type analysis of a
process of text parsing
A.1: Convert a word sequence
into a sequence of stemmed words.
A.1.1: Take
the words in each document and filter out words such as “the” and “a”.
A.1.2: Make
replacements of words into a stemmed class:
running à run
storage à store
etc.
A.1.3: The
set of stemmed classes will be referred to as C.
A.2: Translate the stems to
positive integers randomly distributed on a line segment between 0 and
1,000,000,000.
A.2.1: This
produces a one-dimensional semantically pure representation of the word stem
classes.
A.2.2: The
topology of the line segment is to be disregarded.
A.2.3: A new
topology is to be generated by adaptively specifying the distance d(x,y) for
all x, y in C.
A.3: Introduce a pair wise
semantics
A.3.1:
Following a training algorithm, points are moved closer together or further
apart based on either algorithmic computation or human inspection
A.3.2:
Topologies can be produced by various methods.
A.3.2.1:
Generalized Kohonen feature extraction, evolutional computing techniques.
A.3.2.2: From
one point topological compactification of the line segment, and cluster using
the Prueitt feature extraction algorithm.
A.4: Pair wise semantics can
drive a clustering process to produce a new semantically endowed topology on
the circle.
A.4.1:
Features of the new space are identified by the nearness of representational
points
A.4.2:
Prueitt feature extraction is seen to be equivenant to Kohonen feature
extraction
A.4.3:
Prueitt feature extraction produces a specific distribution of points on the
unit circle.
A.4.3.1: The
Prueitt distribution is defined as a limiting distribution which has
semantically relevant clusters
A.4.3.2: As
in associative neural networks, and other feature extraction algorithms, the
Prueitt distribution is driven by a randomization of selection (of the order of
pairing evaluation), and thus is not unique to that data set.
A.4.3.3:
Iterated feature extraction produces a quasi- complete enumeration of features,
encoded within a topology.
A.4.3.4: The
limiting distribution has a endowed semantics.
A.5: The clustering process can
be mediated by human perceptual acuity
A.5.1: Phrase
to Phrase association by human introspection as coded in a relational matrix.
A.5.2: Latent
Semantic Indexing for co-occurrence, correlation and associative matrices.
A.6: The limiting distribution
is viewed via CCG methodology
A.6.1: The
CCG methodology is linear and assumes a regular limiting distribution.
A.6.1.1: The
CCG technique finds a coloring patterning and modules (related in the number of
columns in the grid), such that a principle of Super distribution can be used
to prove a specific theorem using the limiting distribution.
A.6.1.2:
Coloring pattern and modules is specific to the theorem in question
A.6.1.3:
Given a limiting distribution that is metastable (a pattern is repeated) or
stable (one condition is show to exist always beyond a certain point), then a
theorem exists.
A.6.2: A
non-linear CCG technique might have a grid of dimension higher than 2, as well
as transformation operators that are statistical.
Technical Aside
Locally, the clustered tokens on
a number line can be rough partitioned using neighborhoods (see Figure 1)
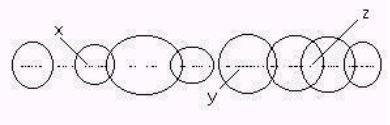
Figure 1: Topology induced by clustering
The circles in Figure 1 indicate
boundaries of categories. These
categories overlap producing areas a ambiguity. However rough sets and the Prueitt
voting procedure anticipates the ambiguous boundaries and addresses this
issue in a non-fuzzy fashion.
We can map the categories to an
n dimensional space. In this case n =
8.
x --> (0,1,0,0,0,0,0,0)
or (0,0.7,0,0,0,0,0,0)
y --> (0,0,0,0,1,0,0,0)
or (0,0,0,0,0.6,0,0,0)
z --> (0,0,0,0,0,1,1,0)
or (0,0,0,0,0,0.3,0.2,0)
Where the first representation
is a Boolean representation of inclusion and the second representation measures
show a degree of closeness to the center of the distribution.
The question of how to assign
category memberships to new text elements is addressed in the tri-level routing
and retrieval architecture and voting procedure as well as in Russian Quasi
Axiomatic Theory.
Domains
There are some important and
general problems in automated recognition of patterns in data streams. When the
stream is a stream of text, then the text can be converted or transformed into
tokens that have been shaped by linguistic and semantic considerations. The discovery of proper shaping methodology
is what is at issue. Shaping is an
induction.
For example, an illness might be
recognized from a written description of symptoms. The text of the descriptions can be converted to number
sequences. Shaping might come from
relevance feedback, or some type of feed forward mechanism such as thought to
account for the shaping of action during motor control, see the
neuropsychological and neural architecture work by James Houk and Andy
Barto.
The development of an
information base from a text database is at least a three step process:
1)
the transformation from text to tokens,
2)
the shaping of token identification, and
3)
the development of relationships between tokens
The first step, in text
vectorization scatter / gather methods, is to randomize the location of numbers
by a uniform projection into a line segment.
The projected numbers become tokens for the text units. The nearness of tokens on the number line is
discarded. Some transformations might
then be applied to produce clusters of values around prototypes of concepts
that are expressed in the text (in theory).
Our hope is that CCG images can
be involved in a visualization of these prototypes. The clusters, once identified can be used in the definition of a
tri-level category policy to be used to place next text elements within an
assignment relative to these categories.
Some Uncertainties
The objective of our study is to
see if we can find a representational schema, transformation of topologies, and
some relationship that becomes clear as a process of analysis moves our attention
deeper into a sequence of numbers or generalizations of the notion of
number. As we neared the completion
of our contract time (December 2000) it became clear to Prueitt that the
generalization of number that we needed is the cluster space itself. The clustering process itself produces
states, and each state in generated from the previous state using a specific
iterated axiom (like the Peano axiom).
.
The cluster iteration is
dependent on a scatter / gather process. This process is well known in the text
vectorization community. We see no way (at least not now) to start with
anything other than a scatter of representational points into a line segment – or
perhaps a n-dimensional sphere (see discussion regarding Pospelov oppositional
scales).
Obtaining the even distribution of numbers is a critical
process. However, there are degrees of
uncertainties that actually play in favor of eventual positive utility. No matter how the distribution occurs,
visual acuity made about distributions in cluster space can reinforce
interpretations of the meaning of cluster patterns that are made by the human.
Reinforcement learning within an
image space?
At the beginning of our current
project (February, 2000), we did not know how we would handle the CCG visualization
task. We felt that the visualization
can come in any of at least three points.
1) In the
clustering process itself
2) In the
provision of semantic linkages between clusters
3) In the
reinforcement of positive and negative learning
Our thinking is that the
identification of tokens should be followed by the identification of a
relational linkage between tokens.
However, how does one impose such a relational linkage given the nature
of human concepts? One answer is a
reinforcement architecture.
A mapping could be developed
between CCG images, derived in some way (see for example, as specified in the
use cases in the last section), and objective physiological, psychological, and
other medical parameters. The mapping might be complex, in the sense envisioned
by the tri-level voting procedure, Russian Quasi Axiomatic Theory, or it could
depend simply on visual acuity. The CCG
– technique separates and then organizes regular patterns using a
two-dimensional grid and color-coding.
We looked for a separation and organization process that makes sense of
non-regular patterns – such as those found in word distributions. These are visualized as point distributions
on a circle.
It might be that normal distance
metrics on CCG – type images might produce an ability to automatically parse
new text for concepts – simply using a distance in image space. Any correspondence between image distances
and conceptual linkages would be of extreme utility. In any case, we need a means to reinforce learning. We need an interface between user and
computational systems. This interface
must be used in critical situations where judgments are made and consequences
determined. The interface must preserve
the notion that human interpretant and judgment is an essential aspect of the
experience of knowledge.
Other Domains
An interpretation of the data
invariance in data from astronomical sources might be made. In this case a relationship would be found
between various types of invariance in the data, as identified by a CCG type
image, and scientific interpretation of that invariance. A reference system could be developed that
extrapolated between visualization.
This domain appears simpler than
the domain of text parsing and a Russian application of CCG visualization to scientific
data streams is expected.
EEG data has been considered,
however, the problem has been the acquisition of data as well as the
development of a methodology for elucidating knowledge from knowledgeable
persons in the field of EEG analysis.
Content Evaluation
Content evaluation seems to be
the most difficult and to have the most potential for a true scientific
breakthrough and for aggressive commercialization. However, we are well aware of the considerations that come from
any proper understanding of the deep issues.
Content evaluation for full text
data bases might follow a specific approach:
1)
a inventory of CCG type images is recognized by a human as having value
2)
the images are used as retrieval profiles against CCG representations
of text not yet recognized
3)
an associative neural network would take reinforcement into account in
the modification of semantic interpretation
Several theorists have
identified a problem. This problem is
stated well by Alex Zenkin when he talks about expert knowledge and the role of
well-defined goals to the CCG based vetting process. We hold that this problem can be solved using ecological systems
theory based in part of the work of Robert Shaw, J. J. Gibson and A. N.
Whitehead.
Comments from Alex Zenkin
VISAD works with any set of
objects that is described by any set of tokens (signs, properties, etc.).
The set of tokens must include
semantics on the set of objects.
The required semantics is
defined by common goals of the problem under consideration (purchase, sale,
advertisement, production, market, etc.). It is obvious, that objects will have
different sets of tokens depending on the goal.
The requirement for
goal-oriented information means that it is impossible to describe all objects
of a large patent base by an unified set of tokens.
Not knowing terminal aims and
semantic features of objects, we can construct a set of only formal
syntactical, grammatical, and statistical tokens.
However, Zenkin sees the
following possibilities.
First of all, we may formulate
the terminal goals
1)
Why we need to analyze the data?
2)
What kind of problems will the new knowledge help us solve?
We may extract from the patent
base a class of related objects (say, by means of key words).
A set of tokens related to
terminal goals must be constructed by professionals in the problem domain
defined by the terminal goals.
We may use VISAD in order to:
1) Visualize the given class of objects.
a. a. The class will have a distinctive CCG – type image that is used as an
icon
b. b. The icon will have possible dynamics.
Zenkin has suggested that Lefebvre type gestured images be used as a
control language
c. c. Prueitt has developed some notion on state / gestures response
interfaces to contextualized text databases.
2) Define more accurately the initial set of tokens
d. a. It is an interactive process of experts with the problem and of
learning their professional knowledge and intuition.
e. b. Our experience shows that professionals frequently find out new ideas
and solutions during VISAD usage.
f.
c. Vladimir Lefebvre's has useful ideas on reflexive
dynamic interaction "expert – an experts group", "expert –
visualized problem"
g. d. Vladimir Lefebvre's "faces representation" for qualitative
analysis of situations might be useful here.
3) Automate (with a visual CCG-support)
classification of the given class of objects
4) Automate (with a visual CCG-support) creation of
notions on classes
5) Creating a mathematical (logical) model of the kind
"What will be IF …" or "reason - consequence", "cause
- effect", etc
6) Automated (with a visual CCG-support) recognition
(purposeful search) of objects in image-structured information base.
Additional comments on VISAD by
Alex Zenkin
VISAD usage allowed us to make
clear well-known information on logical and mathematical paradoxes (about 20
objects described by about 20 tokens). IN recent work in Russia, Zenkin
discovered some new tokens, made a new classification of some paradoxes, and
formulated notions on necessary and sufficient conditions of paradoxicality as
a whole. These notions disclose the
nature of paradoxicality.
Main stages of this work are
described in Zenkin’s paper "New Approach to Paradoxes
Problem Analysis" published in "Voprosy Filosofii" (Problems
of Philosophy), 2000, no. 10, pp. 81-93 (see Annotation, today so far in
Russian.
The VISAD and its usage to
analyze large bases of text unstructured DATA is a large independent project.
Note from Paul Prueitt to Alex
Zenkin November 17, 2000
CCG analysis of EEG data is a
complex task. The data set that Prueitt
received from Pribram’s lab has what is an unknown format of the numbers. Figuring out this format has stopped his
attempt to put EEG data together.
If this data format problem is
figured out, we still have the difficult issue of how to make sense of the
syntactic structure that might be imposed
For this reason, Prueitt has
turned to the unstructured text domain, since he has already solved the
conversion of text to numbers and categories problem.
Prueitt’s hope was that Zenkin
would be able to find both a source of data and the expertise to make a small
experiment in Russia. We hope that
Zenkin is able to solve both these pragmatic problems and thus produce an
prototype application of CCG to unstructured scientific data.
Criterion for knowledge creation
We have developed a metaphoric
linkage between Zenkin’s CCG application to number theory and parsing and
interpretation applications to other data sets. The linkage is related to the notion of induction, Zeno’s
paradox, Cantor’s diagonalization conjecture, and Godel’s complimentarity /
consistency arguments.
In our view, knowledge creation
occurs when a jump occurs from one level of organization to another level of
organization. This jump is referred to
as an “induction”. The scholarship on
this notion of induction is concentrated in the area called ecological physics
(J. J. Gibson, Robert Shaw) and perceptual measurement (Peter Kugler). We hold that inductive jumps require the
existence of scales of organization in physical systems (see the work of Howard
Pattee).
In the case of mathematical
finite induction, the jump occurs when one assumes an actual infinity, and uses
this assumption in the characterization of the positive integers. In the case of Zenkin’s principle of super induction, the
jump allows the truth of the presence of one condition to be transferred to the
proof of a theorem.
Zenkin’s principle of super
induction is still an induction that occurs about formal structures that are
regular and linear, even through perhaps intricate.
One requirement for CCG
application to number theory is the existence of an infinite sequence of
positive integers – generated by the Peano axiom and the imposed property of
addition and multiplication. This
sequence serves as an index on sequences of theorems. The objective of both induction and super induction is to find a
way to demonstrate that the truth of an intricate relationship transfers. The transfer is between secession (Peano
axiom), addition and multiplication properties of integers. This transfer will exist beginning at some
point and then continue being true from that point in the sequence of theorems.
With any representation of
concepts in text, we have a different situation. There is no relevant truth-value that can be assigned to some
relationship between numbers, or so it seems at first glance.
![]()
Section 4: Study of
cluster iterations and visualization
In reviewing the first three sections
of this report, I find the concepts difficult.
We must cover so much. First, we must cover what we have discovered
about the knowledge creating methodology that is applied by Alexander Zenkin to
the knowledge domain of number theory.
Then we have to address what we think are the philosophical issues
related to the notions of induction and super induction. Then we must develop a scientific
foundation and a plan for applying the CCG techniques and concepts to natural
language parsing.
The core issues are:
1) How do we
replace the concept of number with some concept that has something to do with
semantic tokens and linkages between these tokens?
2) How do we
replace the original notion of super-induction so that the replacement has the
same rigor as that discovered by Alexander Zenkin?
We have only begun preliminary
work on the first core issue. The
second core issue remains largely a proper statement of something that needs to
be done, but that has not yet been done.
As we neared the completion of
our contract time (December 2000) it became clear that the generalization of
the concept of number that we needed is the cluster space itself.
The clustering process itself
produces states, and each state in generated from the previous state using a specific
iterated set of rules. These rules
collectively can be thought of as an axiom, which, like the Peano axiom, is
iterated. The visualization of a sequence of cluster spaces requires
considerable work with computer programmers.
However the literature has many examples of visualization of cluster
spaces (specifically systems like Pathfinder and the Spires).
The first elements of the
sequences should show a random scatter of the points. Figure one shows a random scatter of points to a circle.

Random scatter of 312 points on a circle
This is the scatter part of the
scatter / gather methods. The gather part is generally either:
1) take two
points randomly and evaluate the “nearness’ between the two corresponding
documents and use this metric to move the two points a little closer or further
apart on the circle.
2) take a one
and a cluster at random and computer the “nearness” between the document and
the cluster and move the point closer or further apart from the cluster on the
circle.
The identification of a cluster
is a critical issue, and perhaps this is where we might use some corollary to
the CCG visualization. Again, it is
difficult to be specific because there are many different ways to accomplish
something. For example, whereas the
first part of a gather process might be purely algorithmic (using the Prueitt
voting procedure or the standard cosine measure); the second part might allow
the use of visual acuity to select the boundaries of a cluster, and to make a
judgment about the topics and themes that are central to that cluster. Once clusters are identified, then one might
ask a user to review a cluster’s conceptual graph and the conceptual graph
related to the point.
A question can be posed to the
user regarding the “nearness” of the two conceptual graphs. The answer can then drive the gather
process.
The question of nearness is
problematic unless handled in a grounded fashion. The grounding that we suggest is Pospelov’s notion of an
oppositional scale. Pospelov has made
the conjecture that there are 117 categories of semantic linkage. The enumeration of a theory of semantic type
by Pospelov is conjectured to be language independent, and to be related to the
actual linkages that formed when the natural language systems go through the
early formative process. The work of Stu
Kauffman on autocatalytic sets establishes one way to justify the notion that
semantic linkage in natural language in fact has a specific structure. Regardless of how one justified an
enumerated set of dimensions, semantic linkage must be expressed through
degrees of freedom required for each of these dimensions.
The analysis of the previous
paragraph implied that the gather part of a scatter / gather method be made on
a 117 dimensional sphere. The notion of
nearness is thus specific to those oppositional scales that are seen to be
relevant to a comparison such as between two cognitive graphs.
Such comparison is both
situational and relative to a point of view.
Thus the indexing of semantic linkage in text collections needs to be
vetted by human introspection, and the consequences of this vetting process
encoded into some type of compression.
The gather process is exactly such a compression.
No matter how the limiting
distribution occurs, visual acuity made about distributions in cluster space
can reinforce interpretations of the meaning of cluster patterns that are made
by the human. The limiting distribution
reveals clusters that need to be validated as a relevant knowledge artifact in
context. Knowledge validation is where
we expect to seen formal notion related to Zenkin’s notion of super induction.
One requirement for CCG
application to number theory is the existence of an infinite sequence of
positive integers – generated by the Peano axiom and the imposed property of
addition and multiplication. This
sequence serves as an index on sequences of theorems. The objective of both induction and super induction is to find a
way to demonstrate that the truth of an intricate relationship transfers. The transfer is between secession (Peano
axiom), addition and multiplication properties of integers onto an evaluation
of truth.
This transfer of evaluation will
exist beginning at some point and then continue from that point in the sequence
of theorems. The validated limiting
distribution of a gather process has exactly the property we need. At some point the gather process does not
change the clustered patterns. From
this point on the clusters remain invariant.