Proposal to Industry
Data fusion
through stratified data abstraction and visualization
Proposal from OntologyStream Inc
January 2, 2002
Section I: Application areas:
Primary application area: Cyber battlespace planning and response
Other Application: Virtual Knowledge Base Proposal
Relevance: Emerging new technologies are changing the nature of processes that occur in the Internet. These technologies are coupled with a social awareness of the importance of the Internet to civilian and military activity.
Stratified data abstraction is based on an understanding that living systems have selective attention and learning processes that are stratified and use physical properties and laws to behave as individuals and as members of a group. The human sense making system likely has layers of abstraction and manages these layers separately.
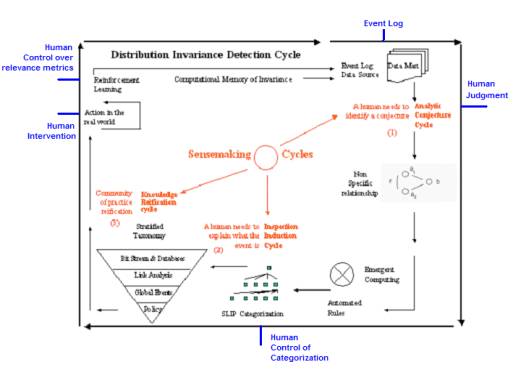
Figure 1: SenseMaking within a Distributed Invariance
Detection Cycle
OSI is proposing to simulate the provision of a "collective unconsciousness" from mobile intrusion detection systems within the Internet. Collective self-control of incident visualization is to be shown, based on stratified data abstraction and visualization.
Stratified data abstraction and SenseMaking Environments are required to interact between these layers of abstraction and human communities (see Figure 1)
The technology reflects “stratified” mechanisms that conjecturally provide a common substrate to human thinking.
Awareness is a property that occurs under conditions that modern science can only now conjecture about. Some scholars have conjectured that these conditions must include a type of cross scale coupling of intentional processes to metabolic and other processes involving exchanges of energy at several organizational levels. We agree that this conjecture is interesting. The experimental cognitive science literature has show to us that awareness is not a simple process, involving only one level of organization. Awareness involves observable interactions, with well-defined exchanges of energy, as well as un-observed causes.
These un-observed "causes" may be related to the substructure of memory and, in quite a different fashion, to the process constraints of the environment. Within this stratified paradigm, a level of organization is defined to be all those things that interact with minimal, or no, un-observed causes.
For example, we would be able to see things only within one level of organization. We do not see the quantum mechanical flux that arrives from the world into our optic nerve. We see the full scene that lay in front of us. Also within this paradigm, multiple levels of organization contribute to the reality that humans see, though only one of these levels can be observed.
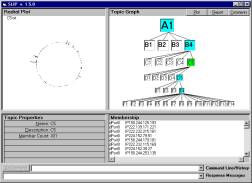
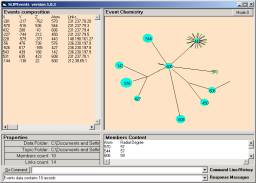
Figure 2: SLIP Interface
Incident visualization follows the same path. The “atoms” form intrusion signatures are aggregated into an event taxonomy using small mobile browsers pictured in Figure 2.
Section II: Primary focus
Phase I will provide a comprehensive simulation environment, perhaps to be used as part of a honeyNet. The simulations will study the details of a medium size collection of distributed mobile intrusion detection systems in conditions under which a substructural memory and ultra structural categorical constraint entangle to produce a situated group response, without direct signaling during the response period.
The "tri-level" architecture is set up in a correspondence with what we feel is feasibly consistent to some conjectures about human awareness. But beyond using the biological model for inspiration, the tri-level provides some algorithms and data structure that facilitates the acquisition and processing of semantic networks.
The code for these simulations will be compact and independent of a traditional relational database. OntologyStream Inc has developed the core code as part of an existing distributed Incident Management and Intrusion Detection prototype system.
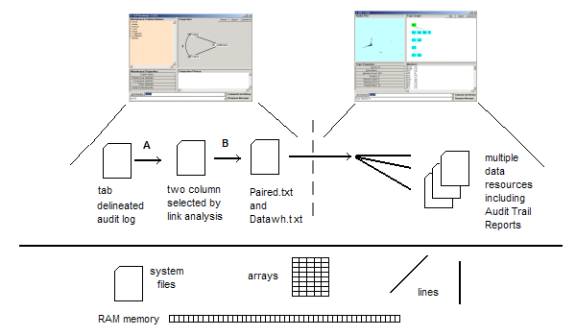
Figure 3: The process model used to create event chemistry
II.1. Potential impact: The Internet is a key Information Infrastructure component.
Informational transparency with selective attention could suddenly and radically reduce costs and increase value from regional Computer Emergence Response Team centers and from commercial IDS providers.
The IDS industry is not looking for break-through technology and methodology. However, the threat of sever economic damage from a cyber ware is increasing. A system of stratified abstractions with a SenseMaking environment could suddenly reduce this threat.
II.2. Current practice: Computer Emergence Response Team centers are manned on a 7-24 basis. The primary information feed to these centers is phone calls, faxes and reports from commercial Intrusion Detection Systems such as RealSecure. Some data visualization tools are used to try to cope with massive data in near real time. Delays in action are often measured in hours and sometimes weeks.
II.3. Limitations of current practice: The management of intrusion detection audit log data is costly due to the demands made on a very limited staff. Incident management is ad-hock and often without any type of systematic re-enforced learning or model building. Knowledge of the past is largely tacit in nature. The knowledge acquisition needed to manage complex distributed hacker incidents is often implicit in nature, and thus not readily captured by traditional expert systems or Petri nets. Most hacker incidents cause damage before detection occurs.
- In most cases, individual humans have case specific implicit (tacit) knowledge that is necessary to open incident tickets and resolve part of the issues presented.
- A different human may have the implicit (tacit) knowledge that is required to generate the task and goal statements that are relevant to achieving a specific collaborative/cooperative task.
For example, collective risk assessment and validation of projected consequences is often only partially attempted and rarely achieved. The existing knowledge banks, of incident scenarios, are riddled with incomplete information or inconsistent information and information having an unknown context. Different scenarios are established implicitly by the physical and locality differences between IDS sensors. Computation with scenarios assumes that the raw data is in fact correct, and this is sometimes also not the case.
One would think that incident report generation would be a relatively simple collaborative task. However, it is possible to see how incomplete data from IDS sensors might make valid incident report generation difficult.
Section III. Contributing technology and methodology
Whereas traditional IDS audit logs provide a degree of assistance, their limitations are well understood.
III.1. Limitations: Intrinsic limitations should condition technology and methodology within the broader architecture that is being proposed. However:
- A complete enumeration of all cases in a rule base is often not available and often-existing data is not relevant to a complex control task.
- A high level of detailed knowledge of the IDS rule base is necessary to fit the expert system around the control task
- The formalization of the rules and logical atoms (tokens) in rule bases relies on the capture of implicit knowledge and on sensor input. But knowledge about new hacker tools is often not available during the period when the most damage is occurring.
Model-based reasoning, case based reasoning, diagnostic reasoning and the methods from the field of intelligent agents can each have limitations that are similar to those found with a traditional rule based IDS systems. These methods also have strengths that should be capitalized on in a selective fashion.
The primary weaknesses are in the following areas.
- The model or reasoning may be missing a representation of critical control elements.
- A high effort is required to fit existing models or reasoning patterns to specific situations, and once a fit is found additional high levels of efforts are required to create software specs and develop code to cause changes to IDS rules based on the conjectured fit.
- Implicit knowledge often does not have the underlying enumeration of causes of knowledge that is likely contributed from human memory mechanisms involved in intuition and synthesis.
The above statement of three classes of weakness is a generalization of the three stated weaknesses of rule based systems.
III.2. Strengths: The strengths of stratified data abstraction and visualization is in the production of a stratified taxonomy and process models tied to data aggregation at:
1) The system call level
2) The IDS audit logs
3) Incident constructions
that allows humans to make rapid correspondences within current realities. Stratified taxonomy allows the discussion of goals and objectives between humans. In some cases, the process models allow an automatic (autonomous) adjustment of operational and control parameters in IDS sensors according to performance measures. This can be affected through a traditional rule base in an IDS system like RealSecure, or in mobile Petri net agents governed by the OSI (proposed) mobile code.
Software supporting diagnostic reasoning can capture the enumeration of characteristic case reasoning and procedures. These characteristic procedures often have the function of solving a problem easily and quickly by moving the system states from a known condition to a known condition.
IV. Automatic analysis using data mining, visualization
and knowledge management:
Data mining and knowledge management terminology has been used to assist in developing a set of atomic patterns.
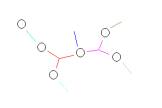
a
b
Figure 2: Abstractions called event atoms (a) are developed using link analysis (b)
The set of these patterns are to evolve slowly when no critical events are occurring, and then used to visualize incidents using a visualization technique, invented by OSI in late 2001, and called eventChemistry.
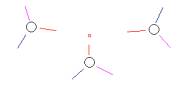

a b c
Figure 3: Event chemistry (a) induces compounds (b) and knowledge structures (c)
The proposed system has three functional components.
IV.1. A structural data base: All available sources of information, are to be retrieved and relevant sections placed into a structural database of two classes of knowledge artifacts, one being stochastic and the other categorical.
Intelligent search agents, having exploratory capability, will carry out the extraction of stochastic invariance in data. Some, but not all, data mining will occur in mobile environments. Reporting will occur through a vetting of data abstraction within three layers of the stratified taxonomy. Each layer has a reporting mechanism that will provide 100% precision-recall of these elements, from the lower level, involved in the data abstraction.
Stochastic invariance will be discovered and coded into a distributed structural database. Categorical artifacts will be generated via a user interface in the form of event compounds having a visual chemical compound appearance. System wide database management and control will be done from a central computer.
The system is to have a special knowledge base containing artifacts (organized into a control language) that "sign" or "point" to general knowledge based on notions of concepts, properties, relationships, and functional dependencies.
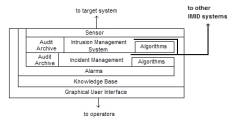
a
b
Figure 4: OSI architecture for Incident Management and Intrusion Detection (IMID)
The OSI knowledge base will have concept space representations of the kinds of sub-events that are composing hacker incidents. The development of the knowledge base will use knowledge engineering practices. Provided sufficient resources, the knowledge base will be delivered as a commercial system using a Mark 2 knowledge encoder developed by Knowledge Foundations Inc.
IV.2. A reasoning system: A highly innovative and advanced reasoning system has been prototyped based on a tri-level voting procedure. Tri-level reasoning develops knowledge of causes of various events, their consequences, possible ways of avoidance of failures or optimization of recourses, for neutralization or compensation; or, on the contrary, activation of such events, as well as knowledge of event mutual compatibility or incompatibility (synchronicity or diachronicity).
IV.3. A data base of cases: The third key component of the system is the Mark 2 knowledge base. This knowledge base stores historical analogs and precedents of historical phenomena, events, conflicts and historically justified ways of solving problems involving similarity analysis and constraint logic.
IV.4. Special inference engines: For real time use, these three system components each have solvers, or special inference engines.
There are three classes of solvers. The first solver, S1, interprets factual data from the structural database and builds a full set of compatible events, using the computational argumentation of the voting procedure. The compatible events are represented in the form of a rough set and a corresponding "policy assignment".
A second solver S2 makes a forecast of situational evolution. This special inference engine determines the set of possible consequences of the full set produced by the first solver, S1. For this purpose, S2 uses properties, relationships and functional dependencies stored in the knowledge base. In theory, S2 can build a full set of compatible events for any new predicted state developed by the engine S1. In case there is a conflict in the predicted state or it contains a conflicting set of events, the third solver S3 looks for appropriate case (cases) in the case base and gives this information to human operators.
If a case has been found, then the solution associated with this case is chosen to suggest this solution to humans. If there is more than one case, a human user forms a new solution out of partial case solutions, by means of a computer/user interface and second order cybernetic system for construction and elimination of rules and inference paths. The solution is then tested for compatibility of its components - by the S1 solver.
Following this model, the system may have an additional module that models the system behavior over time. This temporal logic module takes into account the consequences of decisions being made, and adjusts the decision making to achieve a particular goal.
We anticipate the animation of event compounds as colored Petri-nets. In this animation, we may put the temporal order of sub-events that gave rise to event abstractions. The animation will show the actual sequence of sub-events involved in a specific incident.
V. The relationship between data compression and data
understanding:
Data compression involves the discovery of patterns of invariance that can be used to reduce the bits required to transmit data from one point to another point. In many cases, it is necessary that the transmission be lossless, and that error correcting codes provide a validation that the data received is exactly the same as the data transmitted.
Some transmissions require only a lossy outcome, and in this case the size of the data stream can be reduced an order of magnitude or more. In lossy transmission, it is often also required that patterns of invariance be discovered and perhaps stored as models of the statistical frequencies of prototypes.
Lossy compression is used as a means to understand the relevant or meaning of data, including images. This methodology is called "image understanding', even though the 'understanding' only occurs when results of computations as observed by a human.
We conjecture that the distribution of transmission symbol sets in normal compression can be demonstrated to have high value in incident report generation, when the control is mediated by abstractions derived from data aggregation into abstract classes.
Compression-type artifacts will be used process computer intrusion log files.
The informational states of the intrusion reports will be “compressed” into a dictionary. Link analysis relationships will be established using a stochastic process, developed by OntologyStream and already prototyped for Incident Management Intrusion Detection system use. The elements of this dictionary can then be used to develop event chemistry corresponding to distributed incidents with incomplete and misleading data.
VI. Conclusions: Developing and maintaining a collective agreement:
Our approach has been to develop a tri-level artifact (abstraction) database with common evolution of stochastic and categorical artifacts. The approach is based on a model of human perception and on the notion of stratified reasoning
The proposed architecture will demonstrate how to maintain a common behavioral agreement between mobile agents, small software components that are distributed in location and contextual setting. The agreement is developed in an evolutionary way using low cost opportunities to share atomic behavioral patterns from one agent to another. The behavioral patterns are generated from an aggregation of stochastic artifacts (data invariance from a compression stream) into an assignment of categories. The categorization of "experience", by humans, provides the measure of context. In critical situations the shared experiences are used to validate decisions and assess the risk of these decisions to the future usefulness of the cluster members.
Both classes of knowledge artifacts, statistical type artifacts and categorical type artifacts, are modified and distributed within the collective. This property provides a type of "collective substructure" that is shared in common within the human community and the distributed software agents.