Center of Excellence Draft
Proposal
Developing Anticipatory Responses from
Thematic Analysis of Social Discourse
Friday, October 08, 2004
Slightly edited (October 16, 2005)
Responding to
the RFP
http://nrrc.mitre.org/arda_explorprog2005_cfp.pdf
Sections
Approach 2
Proposed leader, team and roles 7
The Plan 7
Government Champion and Technology Transition 9
Impact 9
Resources 10
Behavioral
Computational Neuroscience Group (BCNGroup.org)
Challenge Problem:
Developing Anticipatory Responses from
Thematic Analysis of Social Discourse
Problem: In everyday activity humans
exhibit anticipation about what happens next.
Humans, and all living systems, exhibit anticipatory behavior as part of
our survival mechanisms. This challenge
workshop brings forward scholarly work on anticipatory systems and test
operational computer programs that answer the question, “what is next?” For living systems, one cannot expect “prediction”
in the sense that one expects from the Hilbert mathematical models of systems
governed by mechanisms. What we might
expect is a type of anticipatory technology that uses ontological modeling as a
means to encode structural knowledge about how complex living systems
change.
In complex systems, what
happens next is not solely caused by what is happening now. What happens next also depends on the nature
of (remote/hidden) causes related to the environment and to the resolution of
internal processes. The use of the
language of “complex systems” in the context of “living systems” is valuable if
one takes the time to examine intentionality, internal entailments such as
personality, and the cognitive-perceptual-response patterns that living systems
are observed to have.
Human anticipation appears
to have three categories of causal entailments;
1)
Causes
consequent to patterns encoded into memory,
2)
Structural
entailment that can be predicted from engineering techniques, and
3)
Environmental
affordance
The anticipatory nature of human
behavior is partially understood by science.
We have evidence about processes involved in individual anticipatory
behavior. We have technology to mirror
parts of these processes. A Roadmap for
the adoption of this technology was developed by OntologyStream Inc in late
2004, early 2005; but the implementation of such technology is blocked by
polemics related to the mythology of artificial intelligence. [1] [2]
Figure 1 illustrates an
anticipatory architecture. This
architecture fits within a second architecture (See Figure 3) producing
actionable intelligence within an organization. Well-refined knowledge management techniques are available in
graduate level curriculum developed by two members of our core team. The two architectures work together.
|
Figure 1: Anticipation and the Tri-level architecture |
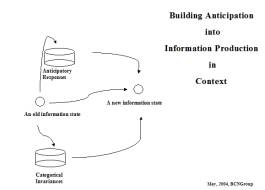
In our preliminary
technology, text is harvested using instrumentation appropriate to
understanding the structures in text. The structure obtained from this
measurement is encoded into a set of ordered triples { < a, r, b
> } where a and b are subjects making reference to elements
of, or aspects of, the measured “structural” ground truth in raw data. The sets are encoded in computer memory as
Ontology referential base (Orbs) having fractal scalability and interesting
data mining features. Temporal
resolution is obtained using categorical abstractions encoded into the Orb
sets. These Orb sets are presented as a
simple graph construction. A human then
views the simple graph.
The graph acts as a
cognitive primer. We call this
human-centric information production or (HIP) because the computer processes
are supportive of a human becoming aware of how information fits together and
as a consequence “connects the dots” and understands something new. This new understanding is easily
communicated within a community. Existing XML and databases can be imported and
expressed as Orb sets. All data
relevant to an investigation is then integrated by harvesting from structured
and “un-structured” data. Information
encoded into Orbs can be re-expressed as XML.
Anticipatory technology
depends on users being well informed about policy questions and objectives of
analysis. This fact runs counter to the
types of information technology systems that the government contractors are
developing for various parts of the federal government. In the standard deployments the focus is on
developing a false notion that human knowledge and human intelligence can be
replaced by smart technologies like web services and W3C standards for semantic
web representations. [3]
Our Approach
Practical considerations: Our algorithms, data encoding
standards and computer interface design methodology have been created to
enhance natural anticipatory mechanisms available to humans. Natural science
recognizes the neuro, cognitive, behavioral, and social dimensions to
anticipation and the use of natural language to support anticipatory
responses. The team leader has long
established correspondences with lead scientists in these fields. The team leader also has extensive contacts
with technologists. The team leader
depends on long established associations to bring together a number of
different technical innovations, and re-express them into a single simplified
capability, based on the Orb encoding [4]. Technical innovations have, can be shown to
have, architectural properties corresponding to natural anticipatory
mechanisms. The team leader has pieced
these technical innovations together from a study of patents on data analysis
and data organization. The correspondences
to natural science are well delineated and can be reviewed by natural science,
using principles of scientific investigation into natural phenomenon.
The following tasks can be
achieved:
Task 1: Create a conceptual indexer,
signature, technology that does not need to preserve individual identities but
instead develops categorical knowledge of behavior and response patterns.
Task 2: Create a polling-type
instrument using web harvest of weblogs
Task 3: Create agile real time web
harvesting processes that reveals the structure of social discourse within
targeted communities
Task 4: Reveal the structure of
social discourse in such a fashion that the results are about the real time social
expression between people and predict tendencies towards actions or interests
Task 5: Develop a common notation
around the representational language so acquired
Technical Considerations: A group of scholars have a common and shared sense that
anticipation technology must involve a theory of a stable substructure of
categorical invariances, a theory of how elements of substructure forms into
phenomenon, and a theory of environmental affordances that constrain the
formation of events. The reason why we
have this shared sense is because the natural science about memory, awareness
and anticipation has become clear over the past two decades. The two computational architectures, one
embedded in the other, reflect this science.
The principle assumption is
that stable substructure of categorical invariances exists. This assumption is certainly reified in the
case of physical chemistry. To
demonstrate that “period tables” exists and govern the formation of events
requires that a generalization of the notion of a periodic table be made. One aspect to this generalization is that
there be multiple meta-stable configurations of “categories of invariance”. A discovery process is thus required.
In our tri-level architecture,
raw computer data [5] is parsed
and sorted into categories. Categories
are defined both using function and structural considerations. The function-structure relationship is
examined for invariance across multiple instances. We make the claim that the examination of function and the use of
substructure are ubiquitous to living systems.
Thus the claim is that natural science finds evidence for a tri-level
architecture in how living system develops memory, response mechanisms and
cognitive capability.
The tri-level architecture
is a model of natural processes related to the development of memory, response
mechanisms and cognitive capability. However, this architecture suffers from an absence of direct measurement
of reality in real time. This
difference between a formal construction, which the tri-level is, and the full
nature of a natural system is noted in a 1995 publication by the team leader. [6]
The correspondences between
natural memory, response mechanisms and cognitive capability and the
computational mechanisms within the tri-level architecture is clear and can be
reviewed by both computer scientists and natural scientists. Within the computational systems, iterative
parsing and categorization seeks the patterns of regularity within various
contexts. Human in the loop is required
because the computer processes cannot “measure” reality directly (as yet).
In the Roadmap [7]
patterns of categories are visualized as very simple graph constructions. A response mechanism is easily used to
subset a set of ordered triples representing the information held by the simple
graph constructions. Patterns of co-occurrence
are reified into higher-level constructions corresponding to the quasi-stable
periodic tables that are discovered through human use of the human knowledge
system. The human in the loop is
essential, and use of human knowledge with this tool results in a science of
events that are specific to the targeted objects of investigation.
Because of the regularities
in patterns, an entire inventory of patterns can be stored in extremely small
data structures. The break-through is
so profound that mechanisms related to the W3C standards and information
technology procurement has been developed to inhibit the demonstration to the capabilities
that tri-level computational systems will soon demonstrate. A discussion of these defensive mechanisms is
find in the BCNGroup Glass bead Games. [8]
The proposed use of the
tri-level architecture for US Customs had two aspects, the first being a
measurement of the discussions occurring within the government during normal
and crisis operations. Orb
constructions are used to inventory co-occurrence patterns found within human
language. In theory, our inventory of
patterns has the capability to do as well or better than latent semantic
indexing (LSI), because the co-occurrence measured in latent technologies is
present in the inventory. This claim
will be tested so as to reveal both the nature of LSI and of Orb sets developed
directly from the LSI transform and from test collections.
The second aspect of the proposed
use of the tri-level architecture for US Customs [9]
has to do with a measurement of harmonized tariff schedule ontology in the
context to administrative ruling regarding the proper payment of tariff, and the
examination of global patterns in commodity transactions worldwide.
A technique for harvesting
some structural properties of neural network pattern recognizers has been
suggested as a homology between the basins of attraction and sets of the simple
Orb constructions in the form {
< a, r, b > }. A mathematical theory about operations on Orbs exists. Thus the Orb data encoding standard and all
advanced “artificial intelligence” methodology can be integrated using a simple
mathematical constructions living within Hilbert space (the formal space
defined as a generalization of three dimensional vector space.)
|
Figure 2: Orb visualization |
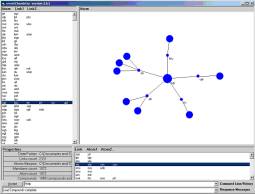
Simple types of Hilbert mathematics
are useful in the context of processing knowledge representations. In both the latent semantic indexing (LSI) case
and in Orbs data mining, if a is an
element of C and b is an element of C, then < a,
r, b>, ie a is conjectured to have a
relationship to b. The elements a
and b can be word occurrences and the C a paragraph. But clustering phenomenon is seen any time
we can express a relationship. < a, r, C >, < b, r, C >
implies < a, r, b
>. The “clustering” using Hilbert
space constructions related to what is formal topological measures of nearness
and association.
The Orb constructions appear
to form a universal means to encode latent information. The underlying notational similarity between
LSI and a set of Orbs also means that latent semantic technology can be used to
help separate concepts and concept groups computed using LSI, or generalized
LSI, and expressed as Orbs.
Our work suggests that one
can extract structure from an LSI transform and encoded this structure directly
into Orb sets. The team leader has
actually developed some results that demonstrate this extraction of structure
from LSI. [10]
Orb sets can be manipulated at the level of the individual members, < a, r, b
>, so as to
effect disambiguation of terms. They
can be easily “added” or “subtracted”.
Orb updates require a single pass rewrite of the Orb. This rewrite is extremely easy to implement,
and the team leader has developed several simple interfaces to perform what has
been called Orb arithmetic.
Within the tri-level
architecture, engineering and human-centric methods are combined. Co-occurrence of word constructions is
treated as a non-specific relationship.
This means, i.e. the use of the non-specific relationship, which co-occurrence
is observed and patterns are measured without attaching meaning to the
patterns. Using our existing, simple,
technology for visualization of Orb sets, humans look at the patterns and
manipulate them (see Figure 2). The
human imposes semantic relationships in real time and may attach metadata to
patterns. Within the second
architecture, iterative action-perception cycles produce thematic Orb
representations of concepts being expressed in text. Theories of type are
developed based on human perception of patterns and personal knowledge. The human in the loop is essential, as is
the Orb encoding of co-occurrence and patterns of co-occurrence.
Team members will organize
an on-line library resource to assist in training and educational
services. Machine algorithms certain
can provide evidence that patterns have specific functions. Humans can quickly reify this evidence if
they have a background in general systems theory and related disciplines. Representations identify concept signatures. But how do signatures come about, and how
might they be used or misused? These
questions are addressed by several academic disciplines including ecological
psychology, social-biology and evolutionary psychology. Team members will develop a broad review of
this literature and develop tutorials on fundamental concepts needed to
understand anticipatory technology.
With Orbs, no other “data
base” is needed. There are no
dependencies on any operating systems, except in the case of user
interfaces. The core Orb database and a
small set of transform methods are developed in C and Python. We plan to develop a Linux server with API
to any remote computer, where the user interfaces will be developed.
Deeper technical discussion,
summary:
Ontology referential bases (Orb) constructions are being developed to store
“localized”, or “schema independent”, information into computer memory. The local information is captured by mining
processes, or developed directly by a human or human community. The generic form of Orb encoding is an
n-tuple in the form: < r, a(1), a(2),
. . . , a(n-1) > where r is a
relational variable and the set of nodes
{ a(1), a(2), . . . , a(n-1) } are references to topics. (See Orb
notational paper [11] The software for viewing InOrb constructions
uses a freeware SLIP browser [12].
Domain and data sets
For the Challenge Problem Workshop we have four types of data sources:
1)
Harvests
from specific weblog sites
2)
Books
in the literature
3)
A
collection of 312 Aesop fables
4)
Extensive
Intrusion Deduction System log files
Orbs have two ways to view data. One is “local”, involving individual
elements of an Orb set, the other is global and is a graph consisting of
information and relationships between information. The Orbs encode “localized” information without regard to
possible global organization of information.
A subset of this local information is made “global” via a class of mathematically
precise transforms called “convolutions”.
In the best case, the localized information is about elements of
“substructural ontology”. In cyber
event space and in the event space of social discourse the knowledge about the
substructural elements is conjectural.
Much of the challenge problem is designed to test this conjecture by
identifying possible organizational principles expressed as a framework. Frameworks have a small number of
“aspects”. Three frameworks, by Sowa,
Ballard, or Adi, have 12, 18 and 32 elements respectively.
User interfaces have to be designed with domain
specific features. Prueitt and Kugler
will supervise this task, with most of the programming done by Nathan Einwechter
(OntologyStream Inc) and Dave de Hilster (Text Analyst International
Corporation). Usability studies will be
developed. The purpose, of the
interfaces, is to conduct an investigation about the structure of event space
using a specific framework.
Our first domain is defined by text collections harvested from the web. Our team has all of the technical capabilities required to create new data sets at will. Our second domain is data available to cyber security analysts. One of the team members, Peter Stevenson, has been working with the team leader, since 2002, on an application of the tri-level architecture to cyber event detection. Stevenson and one graduate student are working on applications with internal university funding. They will attend the challenge problem retreats and will develop reports on their work.
Metaphor to scientific instrumentation: Measurement of structure in the data is instrumented using a set of tools that function like a microscope. The microscope does not provide the meaning of the structures and the functions that these structures have or may have. The meaning of what is perceived come from individual scientists and indirectly from the community of scientists and the literatures that define the science. Through the real time inspection of event space representation, a type of inference develops that depends on the structures that the human sees and on the tacit experiences of the humans. Our core team calls this “mutual induction” since the human mind is primed by the observation of structure in much the same way as text on the page of a novel “causes” the novel’s narrative to be experienced by the reader.
Evaluation
Our Integrated Anticipatory Technology (IAT) process model has nine steps. Each aspect is evaluated separately, and there are two types of evaluation: peer review and on-line workshops concluding with a set of questionnaires. The first two aspects will be evaluated through extensive benchmarking for scalability, compactness and speed. Team members will develop technical papers. The third and fourth aspects require a measurement of structural and functional ground truth. Ground truth is measured in real time at both the substructural [13], and the event layer [14]. Anticipatory responses occur when information is presented to a user via the visualization of simple topological neighborhoods of Orb graphs, as seen in Figure 2. The other six aspects are better understood than the first two. The measurement problem is the less well understood. Orb encoding makes each aspect easier than if one uses a relational database.
|
Figure 3: Aspects of Integrated Anticipatory Technology |
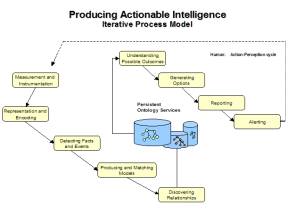
A knowledge management type evaluation program will look at a process model involving the two HIP architectures. One of the team members is Art Murray, Director of the Institute for Knowledge and Innovation, at GWU. He will study the flow of information within deployment environments. Our collaborative environment will be a Groove space having an e-forum, tutorial repository, document repository, real time chat, and whiteboard. In our first evaluation study, university students will be asked to find a set of word patterns that “cover” the meaning of Aesop fables. Students will have two weeks to use our tools and study tutorial materials. These individuals will be initially unfamiliar with anticipatory technology. They will be able to chat with the core team and other members of the evaluation team, but they will not share information about patterns they are discovering. The on-line evaluation will help members of the team develop a deployment and transition strategy for the IC.
Empirical studies show that as one creates a better understanding of a system the natural substructural categories come into focus. The focus is like moving the lens of a camera. At one point, a single set of primitive elements comes into focus. We take as an example the process that Tom Adi used in the study of letter semantics in the Arabic language. A study of the fables, in English, using Arabic letter semantics will be made available as part of the set of tutorials. In this study, we expose a methodology. Evaluation depends on an objective measure of a substructure’s explanatory power in an event space. It is noted that variations in viewpoint may see “different” substructures.
Proposed leader, team and roles
The proposed team leader is
Paul Prueitt. He has integrated several
data encoding methods. He has studied
complex natural systems for over a decade, starting in 1991 while he was
Co-Director of the Neural Network Research Facility at Georgetown
University. He has designed and
supervised the development of several enterprise-wide information systems. His PhD thesis (1988) was on mathematical
models of intelligence exhibited by biological systems. He knows each of the other team members.
Prueitt has been seeking an
understanding of common principles found in mathematical models of control,
models of linguistic variations serving communicative functions, and models of
complex social and psychological phenomenon.
He has developed a standard notational formalism on which to discuss
contributing lines of research. These
lines of research have resulted in the measurement of linguistic variation in
text, ambiguation/disambiguation issues, situational logics, selection of logic
based on state transitions, selective attention, novelty detection,
terminological reconciliation issues, schema issues, and transformations of
encoded data sets. John Sowa’s work on
structural similarity between graphical constructions will be examined in the
context of Orb constructions. Sowa’s
work suggests how analogy can be recognized as similarity metrics between
cognitive graphs. The difference
between cognitive graphs and Orbs will be examined. Richard Ballard’s work on n-ary representation of declarative
knowledge will be examined. The
processes under lying Readware’s conceptual indexing expressed in Orb notation. Elements of poly logics and schema over
logics will likewise be incorporated into our base theory.
Amnon Myers and Dave de
Hilster have many years of experience with natural language understanding
techniques. Ken Ewell, Tom Adi and Pat
Adi have several decades of experience with the theory of language, and have developed
the commercial system Readware ™. Peter
Kugler has published a book [15]
and several dozen peer reviewed papers on anticipatory mechanisms,
intentionality and perceptual measurement.
He has designed a significant number of computer simulations and control
interfaces. Art Murray is Director of
the Institute for Knowledge and Innovation at George Washington University and
has collaborated with Paul Prueitt on taxonomy and ontology development
projects. Murray teaches graduate level
knowledge management courses.
Participants:
The core team consists of: Peter Stevenson, Director of IA, Center for Regional
and National Security, Eastern Michigan University, Art Murray, Director of the
Institute for Knowledge and Innovation, George Washington University. Tom Adi, MITi Inc, Pat Adi, MITi Inc, Ken
Ewell, MITi Inc, Amnon Myers, Text Analysis International Corporation Inc;
Peter Kugler, Kugler Institute; Nathan Einwechter, OntologyStream Inc; Paul
Prueitt, OntologyStream Inc. An Industry
Advisory Board consists of individuals; Nan Gelhard, Summit Racing Equipment;
Todd Horne, Ten magazines Inc; Mike McDonald, Global Heath Initiative Inc;
Peter Krieg, Pilesystems Inc; Richard Ballard, Knowledge Foundations Inc; David
Bromberg, Acappella Software Inc; and Kent Meyers, SAIC. The government champion is Mary Ann
Overman.
The Plan
Our plan is to deploy and transition technologies within the agencies while at the same time we will deploy and transition a commercial system for anticipatory polling and anticipatory marketing. The commercial setting provides an environment in which to develop objective tests regarding fidelity of concept representation, separation of concept representations, and sequencing of expressed concepts in real time. We expect a no-cost peer review from the academic communities and contributions from leading scholars.
Three five-day retreats would bring relevant scholarship forward and demonstrate results in the five task areas (page 2). The retreats will be set up to allow an open participation by any member of the academic or business community, given that they cover their own expenses. Each retreat will fund twelve presentations. Each retreat will develop code design and provide a set of reports. We expect to create structured experimentation to demonstrate general-purpose anticipatory technology. A general theory of frameworks allows us to make comparisons between the Readware ™ framework, Sowa’s framework, and Ballard’s framework. The anticipatory software will have the same interface regardless of the underlying framework.
On
the nature of anticipation: Although many authors have talked about anticipation, the functional
definition of “anticipation” has been hard to specify. The origin of this difficulty has to do with
a dual reference. One reference is to
the present and one reference is to the future.
Something is anticipatory when it is possible to find in the experience of the present a set of dependencies that point to a probable and definable action in the future.
We
rely on a real time measurement of the structure of data reinforced with
information about past co-occurrences.
The human experience of this information becomes anticipatory when
likely future states can be justified under precise criterion.
To
begin with, we have an integration of VisualText, Readware and Orb technology
to produce information about the topics being discussed in a variety of data
sources. Known structural dependencies
might be “instrumented” using VisualText text analyzers in accordance with
functional engineering developed by Pat Adi using Readware methodology. The measurement of substructural patterns
has been encoded as Orb constructions and convolutions over the Orb
constructions visualized as topological neighborhoods defined over a graph (see
Figure 2). A refinement of this
visualization technique will automate the development of domain specific
artifacts, such as the linkage between Readware substructural ontology and
subject matter indicators, expressed as co-occurrence patterns.
A
new visualization interface will be derived from SLIP (Shallow Link analysis,
Iterated scatter-gather and Parcelation) techniques used to produce the graphic
neighborhood in Figure 2. The human
will exercise anticipatory responses based on familiarity with category
patterns organized as graphs and presented visually. In 2005, we will create an interface that provides guidance about
possible future states. This means that
the computer will become suggestive of anticipated states. Orb data processing is designed to bring a
specific subset of co-occurrence patterns to the attention of a human, and to
rely on the human for the anticipatory response. Which subset is revealed depends on an underlying set of engineered
filters focused by context. Machine
suggestive reasoning is based on both structure/function analysis and
statistics.
One of the constraints found in the development of Orb ontology is the time it takes for an expert human to manually identify permissible entities and relationships within the structure of a data flow. The team will produce computational artifacts roughly identifying the permissible entities and relationships in one of several specific domains. How this is done will be exposed and a user interface developed to automate this process.
The
core team and others involved in the challenge problem will use the Groove
collaborative environment. Benchmarks
will be set and monitored. Individuals
seeking to review materials in the Groove environment will be granted access on
approval from the team leader. There
will be three five-day "workshop retreats". Each retreat will support attendance for twelve individuals. Additional participants must pay their own
expenses. The second and third retreats
may sponsor an open two-day mini conference.
Each retreat will start on a Thursday and end on a Monday (five
days).
Our core team has deep experience in web harvesting, including some experience (Prueitt) with the J-39 system. The J-39 system was used in the Department of Defense for harvesting Islamic community web sites for the purpose of measuring the Islamic community’s reaction to Presidential speeches. Team members have harvested university web sites and located the email addresses of computer science faculty (Myers), and harvested political opinion weblogs to provide anticipatory polling over the political social discourse leading up to the elections (Ewell and Adi).
Two of our Industry Advisory Board members (Gelhard, Horne) will be providing selected text harvests as a new product is developed, using Readware, for anticipating the purchases of on-line customers. This project will provide a test domain and additional resources. The e-commerce environment is well understood by Gelhard and Horne.
Prueitt has an understanding
of how VisualText ™ works and the rationale that Amnon Myers had in developing
this software product. He also has a
deep understanding of the text understanding innovation developed by Tom Adi. Gelhard and Prueitt have been collaborating
on how anticipatory web services might be defined within a highly competitive
e-commerce environment. Kugler and
Prueitt have been collaborating for fourteen years. Murray and Prueitt have collaborated for eight years.
Summary: The core team will create a platform independent computational environment based on VisualText, Readware, Orb constructions and Orb visualization. Various means to produce ontology referential bases will be developed, including techniques that encode ReadWare substructural and concept ontologies.
Government Champion [16] and Technology Transition
Our plan is to deploy and transition technologies within the agencies. The two-level ontology structure in Readware ™ knowledge artifacts will be copied into an Orb construction. Patterns of co-occurrence of words, phrases, or letter combinations will be available from VisualText ™. Patterns from Readware ™ and VisualText ™ will make correspondence to specific concepts. A comparison can be made. The resulting encoded two-layer ontology is associated with observed complex system behavior. Applications to the critically important task of understanding and anticipating terrorism will be made. The integration and testing of anticipatory technology will be in a non-secure environment and will move to a secure environment in July or August 2005. A deploy and transition provision is made to contract with a specific individual, not disclosed, having proper clearances and having an understanding of the team leader’s work.
We will assist MITi Inc in the deployment and transition of a commercial Readware system for anticipatory polling and anticipatory marketing. This market deployment will help the team establish ground truth for two-layer ontologies using only the Readware software. Human expertise is required to develop the top level of a specific two level Readware ontology, substructural ontology based on letter semantics and concept taxonomy. The substructural ontology is fixed. The lower lever of the Readware ™ ontology is intellectual property. The new integrated Orb based system will license its use. However, other two layer ontologies will be developed to fit inside of the Integrated Anticipatory Technology (IAT) platform. In fact, the IAT will have a modular design so that the Readware two-layer ontology is a removable module.
We will unify a community of scholars and scientists around a clear exposition of the HIP technology. This community will develop training materials for university curriculum. The deployment of IAT will be accompanied with a liberal arts understanding of the tri-level architecture. Technology transition plans include an option where the user develops IAT knowledge artifacts. A second option will assume that the user will not be involved in the development of the IAT knowledge artifacts.
Impact
Our claim is that the most natural interface between
humans and data structures is a tri-level organization, with the lower level
corresponding to human memory, the middle level corresponding to observable experience,
and the upper level being anticipatory reflexes shaped by the real time
environment. The claim, if shown to be
valid, will help transform knowledge representational theory.
Our
approach is to extend an existing, informal, community whose members have made
past contributions to an emerging science of human knowledge and human
knowledge systems. Our workshops will
develop an exposition of commonalities and open questions. We estimate that this community will grow
because an enabling technology is demonstrated; and a principled grounding in
natural science is made available.
Beta
versions of the enabling technology are deployable now. Community building exercises will make this
technology available with tutorials and scholarship referencing natural and
artificial sciences. Thus we expect
that the one-year Challenge Problem Workshop will permanently change
information science.
Study of temporal
expression:
Event space is visualized as a function of time. As near real time measurement occurs, regularity in the patterns
allows a compressed representation of the data to be separated from the data
source. Orb encoding can be studied for
historical trends. Orb sets allow real
time manipulation of observational duration, assumptions and viewpoints using
mathematical convolutions over the Orb sets.
Analytic behaviors can be studied in an environment where meaningful
transformations of data occur easily and in reversible steps. Predictive analysis can be checked both
informally and with formal metrics. We
just need to properly develop user interfaces.
Resources
A significant award is critically needed to bind the core group together and solve the small problems that keep us for moving forward at a faster rate. We are attempting to create a breakthrough in a venture capital environment where investment in hard to acquire and is repressive in the constraints that come with private funding. The Challenge Workshop will support the completion of dual use products. An ARDA award of approximately $900,000 would allow the core team to develop anticipatory technology and deploy and transition this technology. The administration of the contract will be through one of the universities (as yet to be determined).
Remaining Issues
We hope that our Anticipatory Technology Challenge Problem will be accepted. Our understanding of political science, natural science, mathematics and computer science does not keep us from knowing that management and marketing is essential to our success. We have left open the option of using the 2005 Challenge Problem contract to establish a university center.
Aside from management and organizational concerns, we also have a question related to belief. Clearly Newtonian mechanics provides an anticipatory science when the cause and effect can be known in precise terms, and when there is no complexity. What about events that do occur in non-Newtonian frameworks? Weather is perhaps an example. The idea of mapping the real time expression of new patents into the Patent and Trademark database is illustrative of the type of problem that our Orb technology is designed to address.
Budget
The prime contractor will pass three subcontracts on to Kugler Institute, OntologyStream Inc, MITi Inc. and Text Analysis International.
Overhead has not been calculated.
Subcontracts:
OntologyStream Inc 287,704
MITi Inc 151,360
Text Analysis International 96,240
Kugler Institute 21,120
TelArt Inc 43,120
Sub 599,544
Administrative
Administrative Assistant 27,456
Retreats 23,160
Software 2,000
Usability subcontract 10,000
Transition subcontract 20,000
Graduate student support 42,000
Sub 124,616
Subtotal 724,160
Target budget is $900,000 with university overhead. However we can go to 1.4 million.