ORB Visualization
(soon)
 The development of Ontology Referential
Base
The development of Ontology Referential
Base 
The Reduced to Sentence FCC Copy
Sorted Sentences
into Taxonomy Containers
We wish everyone would join
the bcngroup e-forum and help develop a community based conversation (a bead
game) about the various issues involved in
1) bringing forward the mature knowledge technologies in a useable fashion
2) addressing the knowledge management and social science issues
If you cannot spring for the $75 membership fee, send an email to Nathan and he will wave the fee (Nathan@ontologystream.com) .
Let me restate what this is about. The goal is a Congressional bill providing $60,000,000 to establish the knowledge science by funding leading scholars to write a curriculum on the technology, the social science and the cognitive science.
The development of the Ontology Referential Base

Figure 1: A segment of the Ontology Referential Base and
one of the SM-Indicator Neighborhoods
In Figure 1 we show the SLIP (Shallow Link analysis and Interacted Parcelation) eventChemistry (cA) Browser. A tutorial on this software is available, along with the software from portal@ontologystream.com . Don E. Mitchell developed the software for OntologyStream.
Extending the paradigm
In Figure 1 we show the second ORB system ever developed. The first is an ORB (Ontology Referential Base) for the Aesop fables. The OntologyStream ORB systems use a number theoretic replacement for hash tables, allowing an In-memory mapping of very large text corpus into small constructions. The I-RIB (In-memory Referential Base) was a precursor to the Ontology Referential Bases (ORBs). (This means that the complete software package plus data is small in size.)
Tutorial on the
first FCC ORB and the fable ORB.
As of November 23th 2003 a procedure has been agreed to that will result in the development of an OntologyStream ORB derived from the analysis of a copy of the FCC public rulings (1997 – 2003).
The procedure is as follows:
1: Amnon Myers used the Text Analysis International Corporation Visual Text IDE for developing custom text analyzers to obtain as many good sentences as possible from the Original FCC copy.
1.1: The Visual Text IDE product is called sentenceParser
1.2: sentenceParser is made available to research teams who may wish to modify it to fit other text collections other than the FCC rules collection
1.2.1: Licensing for use of Visual Text products is arranged with Amnon
1.2.2: Modification services available from Text Analysis International
1.3: from the 37,108 documents in the FCC rules collection copy archive will be generated from approximately 2,000,000 sentences
2: Instant Index will next week begin offering a engine that will produce and maintain a small bit-map image that is the inverted index and location of all words on a specific web site. The cost will be less than $250. OntologyStream will be the first demonstration site for the Instant Index search engine, and clients will be able to purchase this engine, installation assistant and taxonomy services from OntologyStream.
3: The sentences will be processed into four separate archives, each accessible using the Instant Index search engine.
3.1: Cleaned FCC Copy with XML metadata tags
3.2: Reduced to Sentences FCC Copy with metadata tags
3.3: Reduced to Sentences FCC Copy
3.4: Sorted Sentences into Taxonomy Containers
3.0: The original FCC rules collection copy archive
4: The Visual Text derived metadata tags are to encode the occurrences of verbs, nouns, verb phrases and noun phrases for research on topological covers or other research projects
Reduced to Sentence
FCC Copy
5: The Reduced to Sentence FCC Copy will have a list of sentences placed into a file. A metadata tag will follow each sentence.
5.1: Format : Sentence. <document number, date>
Sorted Sentences into
Taxonomy Containers
6: The sorting of sentences into categories will follow exactly the Prueitt Voting Procedure (invented in 1997). The voting procedure categories are defined from the elements of Subject Matter Indicator Taxonomy. Entrieva, Stratify or Applied Technology Systems, or other full life cycle taxonomy technology generate SMIT structures differently. However, in each case each taxonomy element has a definition that is, or includes, a profile consisting
7.1: The original publication of the Prueitt Voting Procedure is two pages long
7.2: Nathan will develop an implementation of the Voting Procedure so that sentences from the Sentence FCC Copy will be gathered together into the bins related to an existing taxonomy.
8: The result of the sorting process is that very large text files will be generated with a list of single sentence (and document number + data meta data).
8.1: The fact that we have dates with the sorted sentences will allow a dynamic view of the linguistic variation associated with each element of the targeted taxonomy.
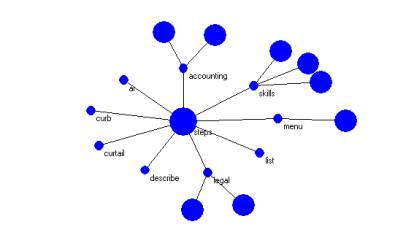
Figure 2: Example of a categoricalAbstraction model of linguistic variation
8.2: The Method for Disambiguation is to be applied to the categoricalAbstraction (cA) model of linguistic variation as applied to the Ontology Referential Base Subject Matter Indication neighborhoods.