ORB Visualization
(soon)
First Tutorial On
SM-Indicators (12/17/03)
Working document on
Subject Matter Indictor
neighborhood
Process Patent Application
Friday, December 05, 2003
This invention uses an exact model of the co-occurrence of words within sentence boundaries and expresses this co-occurrence as a navigatable graph. The navigation of this graph then produces a retrieval profile, the use of which pinpoints exactly where co-occurrence patterns are located. Variation of parameters allows the co-occurrence model to change in scope, from sentence level to multiple sentences and document level. A change in scope is called a change in resolution.
This invention uses a number of well-known techniques, such as stop words, to produce a model of co-occurrence of words and word patterns. The uniqueness of this invention is in the use of a topological neighborhood defined on the co-occurrence graph. Each element of the neighborhood has a center and a radius, where radius is the integer that counts the number of co-occurrence links starting at the center. Standard mathematical topology notation is used to illustrate a well-defined mathematical construction. A topology is a set of sets having properties related to intersection and union.
The topological construction itself is not the disclosed invention, but rather the invention is how this construction is used to produce semantically valid retrieval and metadata elements.
The model is used to provide an exact description of the
co-occurrence of words within text.
This model captures the linguistic variation related to different ways
of speaking about various subjects.
For example, in Figure 1 we have one form of linguistic variation
centered on the word occurrence “orders”.
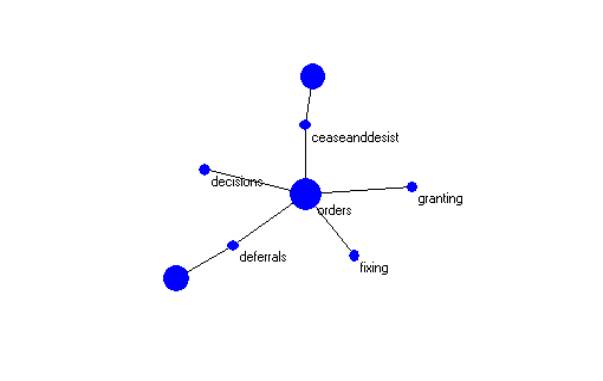
Figure 1: Subject Matter
Indicator for the word-occurrence “orders”
(from the FCC ORB taxonomy )
There are many well known mathematical techniques based on the
use of co-occurrence of words within larger linguistic structures. Latent
Semantic Indexing (LSI), Probabilistic Latent Semantic Indexing (PLSI) are the
most well known. However in both cases,
the exact model of the co-occurrence is not created. In the CCM model an exact co-occurrence is developed, but only at
one level of resolution. Moreover, the
CCM model is not used to produce “differential” retrieval profiles, those
profiles being subject to partial, and differential, use by the user.
The process aspect of this invention describes a methodology
for handling the SM-Indicator constructions both within a community and within
a single user environment.
The mathematical construction, when its graphical
representation is viewed by a human, supports cognitive priming. A cognitive reliance on the represented
information develops from precise and exact information that is highly relevant
to words, sentences or documents submitted by the user through a graphical user
interface. The consequence of looking
at the construction evokes, in a natural fashion, human decision-making
dependant on the precise and exact information forming the elements of the
construction.
The non-statistical nature of the SM-Indicators is unlike
typical text understanding algorithms.
This present invention also involves a method for the
distributed use of Subject-Matter Indicator (SM-Indicator) neighborhoods to
assist communities in the development of fixed metadata constructions, based on
the neighborhoods, and the use of emergent constructions called, within the
context of the present invention, formative ontology. These knowledge management type uses for the present invention
are available as the key element of a cyclic process model whereby human
cognitive acuity plays an essential role in the production of the fixed meta
data construction, having been reified by users or specialists, and in the
identification of new patterns having potential significant to an individual or
group.
SM-Indicators are refined and placed into a controlled
vocabulary by editors and librarians.
Once in this controlled vocabulary, the SM-Indicators are available for
situational modification by editors, librarians and/or users.
As a further reduction of the mathematical construction the
current invention provides a new type of machine inference and pattern
completion. A type of pattern matching
is possible that produces an inference about concepts that might be a subject
within single documents or existing in a distributed fashion across many
documents. Other inferential mechanisms
can be based on the current invention, and are not regarded as part of the
current disclosure. An example of how
the current invention might be used is to produce a machine inference about how
the authors of a document or documents might interpret a conjecture that was
not explicitly addressed in published document repository.
Figure 1: A standard type interface using key words
The current invention uses a standard key word search engine
in an unmodified form. The invention
depends on having two components, a properly reified topology of SM-Indicator
neighborhoods and a standard search engine.
The invention addresses the question of which words a user
should use to obtain the best search results.
Exact and precise co-occurrence information is provided within a easy to
understand visual form.
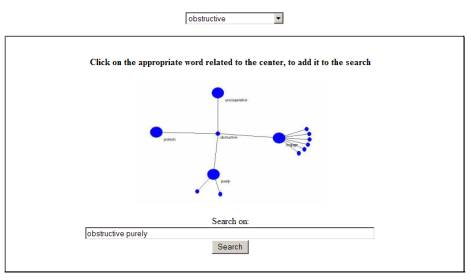
Figure 2: a
mock up of the advanced search interface
Key word search has well known limitations. Using only one word still has a precision recall failure when considered semantically. A single key word, “obstructive”, for example will return all documents that have one or more occurrences of this single word. In the illustrating case, more than 5,000 of the total of 36,118 documents in a repository (FCC ruling 1997 – 2003) are retrieved. Given the two words “purely” and “obstructive” the retrieval has nine documents.
The presence of “purely” in the SM-Indicator neighborhood with center “obstructive” informs the user that in fact one of more co-occurrences of these two words, within the same sentence, can be found. The use of exactly these two words in a key word search will produce all instances of documents having this property.
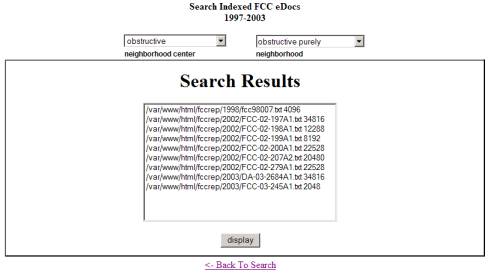
Figure 3: Retrieval of all documents
In Figure 3, nine documents are retrieved. These are all of the documents having both “purely” and “obstructive” occurring in the same sentence. The underlying construction guarantees that only 9 out of 37,188 documents (in this illustrative case) have precisely this property. So in this case the technical precision recall measure is 100%, as in any full text key word retrieval.
The current invention includes a simple and straightforward method in which thesaurus and/or machine ontology is used to disambiguate a single SM-Indictor neighborhood into two or more SM-Indicator neighborhoods – each having a more specific subject indication. A second method is used to produce an ambiguation of a SM-Indicator neighborhood, leading to the union of several SM-Indicators into one.
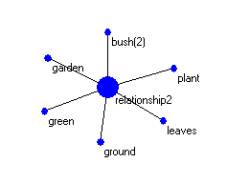
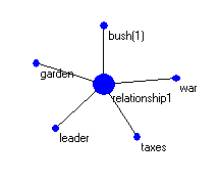
Figure 4: Two SM-Indicator neighborhoods having some relationship
The current invention goes not to the question of how key word retrieval is achieved. The current invention provides any underlying mathematical formulation and a process model for its more effective use. The formulation and the process model together provide a high fidelity between what the user is interested in and the documents retrieved.
The unanticipated aspect of the current invention occurs because so far machine learning and computational linguistics based test understanding systems have not relived on simple human cognitive acuity, depending rather on the false concept that the machine has recognition properties equal or surpassing human ability.
Prototype for Advanced I-ORB
search
Thursday, December 04, 2003