General Framework Theory
Foundations
November 4,
2003
1/8/05: See Functional KM Framework
à
Sept 2, 2002, Central Paperà
The Zachman Framework is used
as a business framework. Zachman’s work
is well known.

Figure 1: The
Zackman Framework
The Zackman framework is created
by taking the descriptive enumeration of the questions:
{ what,
how, where, who, when, why },
and “forming a cross product”
with the descriptive enumeration of persona roles
{
planner, owner, designer, builder, subcontractor }.
Two lesser-known examples of
frameworks are the 12-primitive-element Sowa Framework and 18-primitive-element
Ballard Framework for knowledge base construction.
It is not clear how these
frameworks might be used, but if used in a way suggested by the Zackman
framework, we would have a means to describe each “event” in terms of some sort
of specification of code.
The measurement output from the Ballard
Framework has the form of a 19 tuple:
< a(0), a(1), a(2), . . . , a(18) >
where the value of a(0) is set by a pre-process that categorizes the
event that the framework will be used to characterize.
When any of these frameworks are used, one produces a n-tuple where
each element may have a complex form.
By complex form we mean a two level construction having type as one
level, of description, and value as the other level of description. This stratified construction follows the
notion that structure and function exists at two different levels of
organization. The function is determined
by classes of regularities at the level in which emergence is occurring. Structure is of those regularities that
compose into the thing emerged.
In dynamic complex sets we extend the notion of type to a class and the
notion of value to object.
Note that (type:value) extends to (class:object) when the definition of
class becomes dynamic. In very static
situations the type is fixed and there are no reasons to have an evolution of
the notion of type. However, in dynamic
situations, such as when one does not have sufficient information about
possible types and the profile of types are not precisely understood, then one
needs to have this dynamic evolution of the complex data set.
Using frameworks, the type is derived from the semantic primitive’s
definition. The user, or some other
means, supplies the value. The
framework offers to the human, or algorithmic process, a theory of semantic
primitive. The user, or algorithm, then
supplies specific information into some, but often not all, cells of the
framework thus building a classification profile based on the primitives.
This work suggests the use of the two-level taxonomy as a means to
provide classification profiles.
Suppose that 100 events have been considered.
Domain space = { E(i) | i = 1, . . . , 100 }
A Framework Browser, designed in 2002 by OntologyStream Inc, stores the
cell values as strings, and inventories these strings into ASCII text. A key-less hash table management system
exists that governs the access to the data.
The Browser elicits knowledge from the human clerk and then stores this
in a convenient way.
For example:
A parsing program produces a correlation
analysis and results in a “derived” 18 tuple:
< a(0), a’(1), a’(2), . . . , a’(18) >
where a(0) is an event type and a’(1), . . . , a’(18) are each
slot-fillers that minimally sign the cell contents.
The event type can be used to identify a specific taxonomy or
framework. The complex data set has
the form (semantic primitive, filler) à (type,
value). As information become available
one can develop a definition of an class from information about the occurrences
of the fillers, and the relationships that develop between types.
The task now is to provide a reification process that develops a good correspondence
between classes and object and real world phenomenon.
The derivation process involved a reification of the slot-fillers in
the context of the framework, and this means that a theory of type is developed
for each slot and a theory of relationship is develop between various
slots.
In one version of a frame filing process, there is a reduction of a
free form of writing to a set of standard fillers for cells. Over time, the filling of cells is made from
a pick list. But, using community based
reconciliation processes there is always a means to introduce new types of
fillers at any moment. A type of “open
logic” governs the processes in a Knowledge Operation System.
The set of fillers for each framework cell (a cell is called also a slot
in script theory) becomes the set of natural-kind that is observed to be the
structural components of the event under consideration.
These structural components are the substance of events, such as cyber,
memetic or genetic expression and the discoveries of relationships between
structural elements are achieved using categoricalAbstraction (cA) and
eventChemistry (eC) browsers.
Ontological Primitives, derived by Sowa and Ballard
Linguistic and ontology categorical expression is realized, in natural
language, within the co-occurrence of elements of structure and these correlate
to functional dependencies between framework slots. The senseMaking architecture in the OntologyStream Knowledge
Operating System (OSI - KOS) is then used to annotate these dependencies and to
develop first order logics that provide top down expectancies and predictive
filling in of slots (cells) that have not been filled in.
The slots’ functional dependencies are rendered visually in
the framework browsers.
A Predictive Analysis Methodology using cA/eC is fulfilled in a nice
way. Suppose that 100 events have been
considered.
Domain space = { E i | i = 1, . . .
, 100 }
In each case, the Ballard Framework has been filled out through:
·
Interactive
knowledge elicitation involving human dialog.
·
Some artificial
intelligence process that fills in anticipated cell values using a theory of
type related to each framework slot.
The domain space is now described by
1900 individual data pieces
{ < a(0), a(1), a(2), . . . , a(18) >k | k = 1, . . . , 100 }
where { a(0) k | k = 1, . . . , 100 } are the event names, derived by a prior
process.
{ a(1) k | k = 1, . . . , 100 }
are the (1,1,1) cell values of the 3*2*3 matrix that represents the framework,
and so on.
We will use the notation
{ a(i) k } = { a(i) k | k =
1, . . . , 100 },
for a fixed index element i.
The size of the set { a(i) k } is less than or equal to 100.
If values are repeated then the size of this set is smaller, and can be
quite small, say 4-10 if values are repeated often. This reduction in size of sets is due to the naturally occurring
data regularity in specific context.
The fundamental enumerations of the 3*2*3 framework matrix is as
follows:
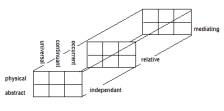
independent (I), relative (R), mediating (M)
physical (P), abstract (A)
occurrent (O), continuant (C), universal (U)
The 18 cells are then derived (by Ballard) as
{ process (IPO), script (IAO), object (IPC), schema
(IAC), measure (IPU), definition (IAU),
participation (RPO), history (RAO), juncture
(RPC), description (RAC), interaction (RPU),relativity (RAU),
situation (MPO), purpose (MAO), structure
(MPC), reason (MAC), law (MPU), formalism (MAU) }
The derivation is
straight forward, for example “mediating / abstract / universal” is rendered as
“law”. So for each of the 100 events,
those aspects of law that are involved in the event is recorded into the
(3,1,3) cell. Ballard justifies this
assignment as “The role played by
physical constraints in limiting choice, function, and achievable
results.”
Data regularity within the Ontological Primitives
We are considering the
Domain space = { E i | i = 1, . . .
, 100 }
described initially by 1900 individual
data pieces
{ < a(0), a(1), a(2), . . . , a(18) >k | k = 1, . . . , 100 }
We use the notation
< a(0), a(1), a(2), . . . , a(18) >k | i
= a(i) k
to be the i-th projection of the k-th framework, so
{ a(i) k } = {
a(i) k | k = 1, . .
. , 100 }
is the set of values that have been placed into the i-th cell across
the 100 events.
So the values for “knowledge ending process” are { a(i) k }.
The regularity of the data is then observed empirically when the size
of { a(i) k } is < 100.
The encoding of this data into type:value pairs enables the graph
traversal and both local and global convolutions as defined in the Notational
Paper at:
http://www.bcngroup.org/area2/KSF
The use of these frameworks may
allow one to map
vulnerabilities/threats
structure/function
substance/form
demand/supply
using
multiple separate analysis of events - seen from different viewpoints.
A cross
level analysis of the relationship between substance and form, from phonology
co-occurrence in audio recordings, can also be established as a means to
predict function from a partial or incomplete observation of sub-structure.