Generalized Framework Theory
Dr. Paul S.
Prueitt
CEO,
OntologyStream Inc
Chantilly,
Virginia
September
2, 2002
http://www.ontologystream.com/beads/frameworks/generalFrameworks.htm
Introduction
We have projected a physical
theory of structural constraint imposed on formative processes, to a
computational architecture based on frameworks.
Various forms are conjectured to
exist as part of emergent classes, and in each case each class of emergent
types has a periodic table – like, in many ways, the atomic period table. This is conjectured by a number of
independent groups, including the Zachman Institute for Framework Advancement and
others.
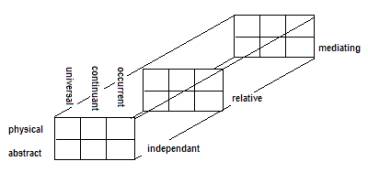
Figure: A Knowledge base Framework
Our
work is formal, and will be difficult to understand without background. However, the group is most anxious that the
concepts be clear in exposition from first principles. This paper lays out these first principles.
Section 1: On the nature of an Enumerated Framework
We
start with the Zachman framework.
Quoting
Inmon, Zachman, and Geiger (Data Stores Data Warehousing and the Zachman
Framework, 1997) page 48:
“By
applying methodologies linked to architectures such as the Zachman framework,
businesses can gain the necessary control over the distributed computer
environment, while taking advantage of the technological capabilities for
quickly providing business functionality.”
And
then on page 52:
“According
to Alvin Toffler, knowledge will become the central resource of the advanced
economy, and because it reduces the need for other resources, its value will
soar. (Alvin Toffler, Power Shift,
1990). Data warehousing concepts,
supported by the technological advances which led to the client/.server
environment and by architectural constructs such as the Zackman Framework, can
prepare organizations to tap their inner banks of knowledge to improve their
competitive positions in the twenty-first-century.
Before
we critically examine this viewpoint, let us look briefly at the Zachman
framework itself. One should study the
framework as presented by the Zachman Institute as the Institute is the
authority on how Zachman frameworks should be used and interpreted. Their conjecture is that the Zachman
Framework is a universal in a specific context.
Zachman
takes two dimensions of Descriptive Enumeration (DE). See PowerPoint side 6 at “DE”. The first dimension is “perspectives” and
the second dimension is “interrogatives”.
Perspectives are: {
planner, owner, designer, builder, subcontractor }
Interrogatives are: { what, how, where, who, when, why }
The framework is formed using a
cross product of these two dimensions.
One way of looking at the cross product is as a matrix. In this case we have a 5*6 matrix, with 5
columns and 6 rows. The cells of the
matrix are indicative of a role and a question.
So < planner, what >
is the (1,1) “element.”
One can turn this element into a
question: “What is the planner?”
As various situations arise the
answer to the question varies. Over a
large number of situations one will begin to enumerate a “complete” set of
answers.
Another name for the cell is
“slot” and the set of answers are called a set of “fillers”. This terminology comes from the field of
artificial intelligence.

Figure 1: The most abstract form of the Zachman
Framework
The
idea is that in a specific situation one can provide a
description of the situation by filling in each of the cells of the
framework. Some might see the
relationship between this notion and the Schank notion of a script with slots
and fillers. The script is one of these
matrices and the slots are the cells.
The fillers are the type of things that are placed into the slots in
specific classes of situations.
In the
language of categoricalAbstraction (cA) and eventChemistry (eC) we have that
the fillers are potential atoms of event compounds, slots serve to provide the
binding of atoms into the event compound and the script (or framework) is in
fact the relationship.
So a Zachman Framework (ZF) can be expressed in the form of a 30 tuple:
< situation, (1,1), (1,2), . . . , (5,5), (5,6) >.
With the situation name being a zero-th element of the n-tuple. The cells are atoms and the situation is the link relationship.
The ZF is a universal for one class of complex processes, but that other frameworks exist. Two other examples of other frameworks are:
- 12 primitive-element Peirce-Sowa Framework or
- 18 primitive-element Sowa-Ballard Framework
Both of
these are used for knowledge bases construction.
One way of obtaining a knowledge
base consisting of categorical invariance is to use the same framework over and
over again in various situations, and note the commonalities of occurrence in
regard to the fillers. For example,
suppose that each “crisis” in a crisis management organization like FEMA would
convene a virtual meeting in a lotus notes quick place. Suppose then that the first order of
business was to fill out the cells of the framework in Figure 1.
Over time one will develop a
pattern completion capability where partial information will identify a
potential filling out of the slots. One
might also begin to also see a predictor of how the organization ends up
responding to categories of situations as designated by a partial substructural
specification. The “system” is then
anticipatory and automated process can begin to stage responses so that if and
when humans decide to act the staging will be in place.
The intelligence of the system
is strongly dependent on
1) The way that humans fill out information into the
frameworks, and
2) The way that human interpret the information once this
information is in the framework
Any intelligence vetting provided
by this set up has exceedingly simply computer science, and exceeding simply to
train a community of practice to use.
Methodology is involved in providing structure to the human computer
interaction. Descriptive enumeration is
used to develop the structure of a framework.
Once the framework is in place, the human in the loop is guided to
provide enumeration of event patterns.
For a clear presentation of the
original definition, by Prueitt, of Descriptive Enumeration (DE) as a
technique, please see the URL.
Section 2: The Generalized Framework
In the
theory of categoricalAbstraction (cA) and eventChemistry (eC) we have that
fillers are potential atoms of event compounds, slots serve to provide the
binding of atoms into the event compound and the script (or framework) is in
fact the relationship between atoms.
The
Generalized Framework (GF) has the form of a n tuple:
< situation, a(1), a(2), . . . , a(n) >
The n-tuple has n atoms and one relationship, so we are defining this is a non-standard fashion.
Now suppose that we have looked at a number of relationships. By this it is natural to think of the situation as the relationship and the atoms as the constituents of the relationship. This means that relationship and context are almost the same notion.
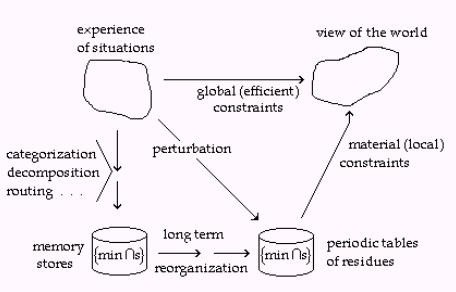
Figure 2: The process flow
model of human memory formation, storage and use.
In the draft of Chapter 7 of Foundations of Knowledge Science,
Figure 2 appears as a model of human memory formation, storage and use. The details about minimal intersections and
residues are in Chapter 9, on the Mill’s logic.
The GF serves as the means to categorize the atoms
into classes, decompose the situations into n-tuples and rout the atoms through
an associative memory mechanism.
Suppose we have a number of events “experienced” and each of these events are decomposed into elements, by filling in the cells of a Zachman-type framework with natural language phrases. One can take the phrases and produce an ontology that provides an interpretation of each of these phrases into elements of the ontology. This is easiest if rich machine ontology (a dictionary of terms) is available and the cells of the framework are filled primarily in terms of, or with the direct use of, terms in the machine ontology.
In the simplest case we assume the later, that the cells are almost always filled by preexisting “fillers” (to use the Schank terminology), where the fillers where already atomic elements related in a correspondence to elements of a machine ontology.
In the more difficult case, from the technology point of view, we need to allow the user to place whatever information or designation into the cells, and then modify the ontologies and bag of fillers to adjust to the human input. The general architecture, for co-evolution of human-language-use and machine-ontology, fits within the senseMaking architecture (use IE as this is a PowerPoint presentation) developed by Prueitt in 2001, with the help of Dennis Wisnosky (Founder of Wisdom Systems).
It is natural to think of the situational
event as the relationship and the atoms as the constituents of the
relationship. Experience is then broken
down into, or decomposed, into the invariance that occurs more than one time
across the set of experienced events.
The Generalized
Framework (GF) serves as the means to categorize the atoms into classes,
decompose the situations into n-tuples and rout the atoms through an
associative memory mechanism.
As a first step
we “measure the data invariance to obtain the atoms”. This measurement sets up
the associative memory mechanism. The
associative mechanism acts on a regime of evaluative inputs (utility function)
and evolves associative linkages between atoms in various contexts. We have a type of adaptive evolution of a
measurement of invariance into data regularity in context (or we might call
this “eventChemistry”).
Suppose that the
i-th event in a collection of events is designed “E(i)”. Suppose that
E(i)
is decomposed into <
situation(i), a(1), a(2), . . . , a(n(i))
> .
Then we can “bin” the occurrences of
instances of atom types, so that
{ < situation(i), a(1), a(2), . . . , a(n(i)) > } =
{ E(i) | i ranges over some index set }
defines the set of atoms required to be
stored in the memory.
Each of these atoms/atom-types has a set
of valances to other atoms depending on various convolutions (measurements)
such as co-occurrence. These atoms look
like what we were finding using the early OSI
SLIP browsers.
Look
again at the Zachman framework. Filling
in each of the cells of the framework develops a description of a situation.
The
Generalized Framework (GF) has the form of an n tuple:
Event à < situation, a(1),
a(2), . . . , a(n) >
In this case the Zachman Framework contextualizes the situation or the contextualization is about some other framework, such as a framework related to a computer intrusion event, or a distributed cyber event.
For a
specific type of event, relationship and context are almost the same
notion. The cells of a framework are
related by the event. Multiple events
of the same type can be described by using a common framework. This is done in computer intrusion event
detection systems but without the full DE based construction of the information
extraction processes. The Intrusion
Detection System (IDS) log file is a 1 * q framework where q is the number of
columns in the log database. The
contents of the cells are automatically written out to a log file.
One
should reflect on the fact that the content of the IDS framework cells are
often populated by a function call of some type. Different IDS have different log files. Sometimes a cell is left empty. For IDS log files in no cases is the cell
populated with two contents. These
reflections will be picked back up in a later Generalize Theory of Frameworks
(GTF) bead. For now we only suggest
that as a human team fills out a Zachman type framework, we often have
uncertain information, information that will change over time and incomplete
information. The information may be
self-deception, or the consequence of mis-information from an opponent.
The information at the beginning may be partial, and yet by calling into the event knowledge base; various automated filling out of the other cells is certainly possible. This provides one level of predictive analysis.
A Generalized
Framework (GF) serves as the means to categorize atoms into classes, decompose
the situations into n-tuples and rout the atoms through an associative memory
mechanism. The associative memory
mechanism and the Matrix of verb forms, being developed by Don Mitchell, are
related.
The SLIP browsers
take as input an ASCII file with two or more columns. Two of these columns are selected and one of these becomes the
relationship type and the other becomes the atom type.
In the intrusion
detection system log files we have no choice over how the log records are
produced.
The first place
that we have a decision is over which two columns to select from the log file,
and this is done with the SLIP Warehouse browser.
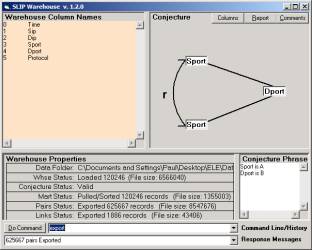
Figure 3: The SLIP Warehouse Browser See any of the OntologyStream tutorials.
What
the warehouse does is to develop the categorical Abstraction (cA) defined by
the link analysis conjecture. In the
classical SLIP browsers the cA are of two types, link types and atom types.
As a
generalization one can imagine having m classes of link types and n classes of
atom types:
Event à < situation(1),
situation(2), . . . , situation(m), a(1), a(2), . . . , a(n) >
But this does not match the notion of a GF. In the GF we have only one link type, but we also have n atom types (one for each cell in the framework). The link type is further sub-classed using an external taxonomy of event subtypes each event subtype “sharing” the same GF. This is an important point.
OSI and
the BCNGroup are working on are CLIP (Complex Link analysis, Iterated
scatter-gather and Parcelation) browsers.
The CLIP technique is defined as follows: we take GF, as input
mechanisms, and convert the values in the framework to the values in the
n-tuple.
The
first value of the n-tuple is an event type.
This event type is already known because the instance of filling out the
framework identified the event type.
This is to say that a prespecified event type as a “filler set” over the
GF. This filler set is from an external
taxonomy.
Set of event types = { situation(1), situation(2), . . . ,
situation(m) }
and in
each case the same GF is called up and values placed into the GF cells.
Over a
period of time, one of the situation types, say situation(k) may be repeated
with some of the associated cell values having variations. In this case, and this case only, we begin
to produce cA atoms.
These
cA atoms are then processed by the CLIP Warehouse.
When the CLIPCore Browser is opened and the data imported, the various types of category atoms are made available for the scatter-gather process (to produce higher order categories), and for visual rending of atoms and links. Each atom type is given a different color. And, because we are using GF to structure the input stream, we have only one type of “non-specific” relationship. The values that this non-specific relationship takes are from the open set which is a set defined in the naming of the “events” that are identified by some (un-specified) process. These events are identified in various ways, but once identified a GF is called forward and the cell values filled in (again in some un-specified fashion). This is the input stream to the event Chemistry (eC) processes.
The use
of the CLIP system over time will “learn” the event categories that provide the
least amount of un-expected clustering in the scatter-gather (stochastic)
process seen in the Core Browser.
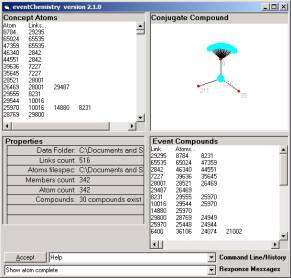
Figure 4: The Event Chemistry
view of category icons
Once
this stability regime has been found then any new clustering is really the real
time detection of a new event type.
This novelty can be immediately checked. The CLIP system can be set up to automatically send notices on
the event of an unexpected event.
Several scales of invariance detection are at work and so the unexpected
event is likely to really be something new.
The
stability regime is found by reintroduction and re-definition of the situation
types in equation 3 using a simple form of evolutional programming (derived
from genetic algorithms). A utility
function makes adjustments so that a mismatch signal is reduced.
The
utility of a framework, any framework, includes:
1)
The framework is used over and
over again to provide commonality to analysis
2)
The framework has a
completeness to the range of information that can and should be gathered during
the information gathering phase
3)
The framework allows
individual “cells’ to be focused during knowledge elicitation independent of
other considerations so that an abstraction over the multiple instances of
analysis occurs naturally.
One can
think of frameworks being used in various ways. But the use of the Zachman Framework in IT market research has
been well established. The value that
our categorical Abstraction (cA) work will have to this is just being
discovered.
Example
1: The categorization can be the name of a DARPA R&D program that is to be
characterized in the framework. Of
course the name of the program is not a “categorization of an event” but is
simply a label.
Example
2: Technology offering for vendors that have been successful in previous
competitions.
The conceptual space being
defined by Example 1 and Example 2 can be compared. For course we can then see the impedance mismatch that has been
talked about elsewhere.
In other uses of the same tool
set (the OSI development environment), the pre-categorization provides a feedback loop
to the clustering of category contents using the SLIPCore Browser. This is a more complex case to explain. Hopefully once the functionality of the OSI
browsers are seen by a user, then feedback loops will be used to iterative
refine a knowledge base and the various sets of natural-kinds that we
developed. This is following the senseMaking
architecture.
Suppose that the “event” is the
elicitation of tacit knowledge about the R&D program that is derived by a
human clerk while looking at the textual description of the R&D
program. The clerk is to answer each of
the thirty questions in the framework.
Who is the subcontractors, or
when is the work to be done.
Note that the when /
subcontractors may have a number of separate answers, and even variations in
how the question is posed. But the task
of the clerk is to answer however it seems best and not to be overly concerned
about the details. Consistent with a
methodology that we see expressed in Acappella Software (a knowledge
elicitation/vetting system) the task of the clerk is to fill out as much as
is comfortable and in any way that the clerk feels fit. So some cells will not be responded to, and
some will have perhaps several paragraphs written. This methodology is also consistent with the Method
of Descriptive Enumeration (PowerPoint URL).
Over time, suppose that 100 of
these events have been considered. The
OSI Framework Browser (currently under design by Don Mitchell) will have stored
the cell values as strings, and will have developed an XML type text file for
each of the 100 events. An I-RIB will
exist that governs the access to the data in the XML. The OSI Framework Browser elicits the knowledge from the human
clerk and then stores this in a convenient way.
A
parsing program is then launched from the OSI Framework Browser. The parser produces a correlation analysis
and results in a “derived” n tuple:
< a(0), a’(1), a’(2), . . . , a’(n) >
where a(0) is the event type
(name of the R&D program) and a’(1), . . . , a’(n) are each fillers that
minimally sign the cell contents.
The derivation of minimal signs
will be fully demonstrated, but there is a great deal of flexibility here in making
what is essential.
There is a reduction of a free
form of writing to a set of standard fillers for cells. Over time, the filling of cells might often
be made from a pick list; as long as there is always a means to introduce new
types of fillers at any moment. The
reverse is also possible if one has a natural language generation capability
such as in the Acappella Software or Wycal’s linguistic ConText engine (now not
longer a part of oracle “full text retrieval” capability). A Cyc knowledge base
type first order logic might also be employed in the standard Schank-type
scripts with slots and fillers and predictive methodology. This will even work in the Intrusion Detection
Architecture proposed to Industry last year by OSI.
The set of fillers for each
framework cell (a cell is called also a slot in script theory) becomes the set
of natural-kind that is observed to be the structural components of the event
under consideration. These structural
components are the substance of the events, and the discoveries of
relationships between structural elements are to be viewed using the
categoricalAbstraction (cA) and eventChemistry (eC) OSI Browsers.
Categorical expression is
expressed within the co-occurrence of elements of structure and these correlate
to functional dependencies expected by the R&D program. The senseMaking architecture for the OSI
Knowledge Operating System (OSI - KOS) is then used to annotate these
dependencies and to develop first order logics that provide top down
expectancies and predictive filling in of slots (cells) that have not been
filled in.
Several other features are to be
discovered with this very simple system.
The total size of the system (of five OSI browsers) is less that
600K. As the system is used, the
knowledge base grows but is always preserved as ASCII text files that are
editable and which are read in at the beginning of the use of the KOS.
OSI expects to have the first release of the Framework Browser available by October, 1, 2002. The complete KOS development environment is available at a year license of $19,500. This license comes with ample tutorials and 160 hours of consulting and customization.
The predictive Methodology using
cA/eC is fulfilled in a nice way using the Generalized Framework in senseMaking
architecture.
One may conjecture that perhaps the Zachman
Framework is a universal for one class of complex processes, but that other
frameworks exist. Two examples of other
frameworks are the 12 primitive-element Sowa Framework and 18 primitive-element
Ballard Framework for knowledge base construction.
Section 3:
The Sowa -Ballard Framework
The
Sowa-Ballard Framework (SBF) has the form of an 18 tuple:
< a(0), a(1), a(2), . .
. , a(18) >
Where the value of a(0) is set
by a pre-process that categorizes the event that the Framework will be used to
characterize. How these values are set
is subject to some considerations that Ballard (“On the Evolution of a
Commercial Ontology”, pre-print not yet available publicly) is making known and
perhaps there are some innovations that OSI
will make also. What is proposed here
is that human action
perception cycles be enhanced with a tri-level
computational architecture that mimics memory, awareness and anticipation
states.
Suppose that 100 events have
been considered.
Domain space = { E(i) | i = 1, . . . , 100 }
The OSI
Framework Browser stores the cell values as strings, and inventories these
strings into ASCII text. An I-RIB exists
that governs the access to the data.
The OSI Framework Browser elicits the knowledge from the human clerk and
then stores this in a convenient way.
A
parsing program then produces a correlation analysis and results in a “derived”
18 tuple:
< a(0), a’(1), a’(2), . . . , a’(18) >
where a(0) is the event type and
a’(1), . . . , a’(18) are each fillers that minimally sign the cell
contents. The derivation process
involved a reification of the fillers of the frameworks slots, and this means
that a theory of type is developed for each slot and a theory of relationship
is develop between the various slots.
There is a reduction of a free
form of writing to a set of standard fillers for cells. Over time, the filling of cells might often
be made from a pick list; as long as there is always a means to introduce new
types of fillers at any moment. A type
of “open logic”, related to QAT,
governs the introduction of new types of fillers.
The set of fillers for each
framework cell (a cell is called also a slot in script theory) becomes the set
of natural-kind that is observed to be the structural components of the event
under consideration. These structural
components are the substance of the events, and the discoveries of
relationships between structural elements are to be viewed using the
categoricalAbstraction (cA) and eventChemistry (eC) OSI Browsers.
Categorical expression is expressed within the co-occurrence of elements of structure and these correlate to functional dependencies between framework slots. The senseMaking architecture for the OSI Knowledge Operating System (OSI - KOS) is then used to annotate these dependencies and to develop first order logics that provide top down expectancies and predictive filling in of slots (cells) that have not been filled in. The slots functional dependencies are rendered visually in the eventChemistry browsers.
The predictive Methodology using cA/eC is fulfilled in a nice way using the Generalized Framework in senseMaking architecture.
Section 3: Ontological Primitives, derived by Sowa and
Ballard
Suppose that 100 events have
been considered.
Domain space = { E l
| l = 1, . . . , 100 }
In each case, the Sowa-Ballard
Framework has been filled out through:
1) Interactive knowledge elicitation involving human dialog.
2) Some artificial intelligence process that fills in anticipated
cell values using a theory of type related to each framework slot.
The
Domain space is now described by 1900 individual data pieces
{ < a(0), a(1), a(2), . . . , a(18) > l | l = 1,
. . . , 100 }
{ a(0) l | l = 1,
. . . , 100 } are the event names,
derived by a prior process
{ a(1) l | l = 1,
. . . , 100 } are the (1,1,1) cell
values of the 3*2*3 matrix that represents the framework,
and so on. We will use the notation { a(i) l } =
{ a(i) l | l = 1, . . . , 100
}, for a fixed index element i.
The size of the set { a(i) l } is less than or equal to 100. If values are repeated then the size of this set is smaller, and
can be quite small, say 30 or so if values are repeated often. This reduction in size of sets is the data
regularity that we are looking for and will visualize as categorical
Abstraction.
The 3*2*3 framework matrix is
derived in Ballard’s upcoming paper: “On the Evolution of a Commercial
Ontology”. The fundamental
enumerations of the three dimensions are as follows:
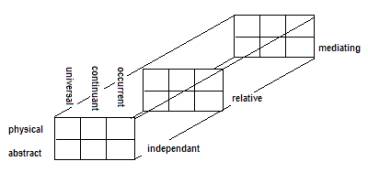
Figure 6 The Sowa-Ballard Framework
independent (I), relative (R), mediating (M)
physical (P), abstract (A)
occurrent (O), continuant (C), universal (U)
The 18 cells are then derived
(by Ballard) as
{ process (IPO),
script (IAO), object (IPC), schema (IAC), measure (IPU), definition (IAU),
participation
(RPO), history (RAO), juncture (RPC), description (RAC), interaction
(RPU),relativity (RAU),
situation (MPO), purpose
(MAO), structure (MPC), reason (MAC), law (MPU), formalism (MAU) }
The derivation is straight
forward, for example “mediating / abstract / universal” is rendered as
“law”. So for each of the 100 events,
those aspects of law that are involved in the event is recorded into the
(3,1,3) cell. Ballard justifies this
assignment as
·
Definition: “The role played by physical constraints in
limiting choice, function, and achievable results.”
·
Representations: “Science,
phenomenology, physical theory, statutory and statistical laws, human nature,
economics, life experience, common sense, heuristics.”
·
Views: “Rules and conditions
with immutable consequences.”
The other cells are also so justified.
Section 7: Data regularity
within the Ontological Primitives
We are considering the
Domain space = { E l | l = 1,
. . . , 100 }
described
initially by 1900 individual data pieces
{ < a(0), a(1), a(2), . . . , a(18) > l | l = 1,
. . . , 100 }
This data is often to be entered
into a file system designed to be converted into the OSI Knowledge Operation
System In-memory Referential Information Bases (I-RIBs) for fast and
interoperable computations. We use the
notation
< a(0), a(1), a(2), . .
. , a(18) > l | i =
a(i) l
to be the i-th projection of the
l-th framework, so
{ a(i) l } = { a(i) l | l = 1, . . . , 100 }
is the set of values that have
been placed into the i-th cell across the 100 events.
The regularity of the data is then observed empirically.
Section 7: Mapping
Viewpoints and Differences Between Viewpoints
The use of these frameworks
allows one to map
vulnerabilities/threats
structure/function
substance/form
demand/supply
using multiple separate
analysis of events - seen from different viewpoints. A cross level analysis of
the relationship between substance and form, from phonology co-occurrence in
audio recordings, can also be established as a means to predict function from
sub-structure.
We have conjectured (August
14, 2002) that the function of a phone call might be thus reduced to a set of
semantic primitives that are language independent. The cross level analysis is consistent with Prueitt’s theory of
stratified complexity, but as yet has not been tested. Testing this conjecture would be straight
forward provided the availability of properly annotated voice communications in
the various contexts of interest.
cA/eC is used to visualize the
categories of data regularity and to develop the co-occurrence maps for
generalized latent semantic indexing.
Human annotation is then possible using the existing OSI
browsers.
So, for example someone can use the
Zachman Framework at DARPA or NSF as this person examines the descriptions of
active R&D programs.
A different person who is in
industry would review the same documents and obtain a different set of
descriptive elements - reflecting the company’s capabilities and wishes.
More interesting, perhaps, is the
comparison of the viewpoint of the program manager and the industry
person. One is interested in an overall
picture of R&D from the institutional viewpoint, whereas the other is
interested in new business development.
The technique would appear to be a process for mapping the
market potential for company capabilities.
The Sowa-Ballard Framework is considered to be more general than the Zachman Framework. At issue for General Framework Theory (Prueitt, 2002) are such things as formal or semi-formal translation of content from one framework “form” to another framework “form”. The naming of the enumerations provides part of the definition of a framework form, as does the dimensions of the framework matrix. Such Schank type scripts (with slots and fillers) has been part of the AI literature, and because data entry forms are frameworks (but not often recognized as frameworks), we have the basis for examining data regularity within context where the data is acquired from humans via a framework. In most cases the ‘frameworks” are not well enumerated and reflect underlying problems with data modeling using Codd normal form relational databases. Some, such as the CoreTalk group, see this confusion over data models diminishing as the frameworks are learned through experience.
The frameworks do not lead to the same type of database
system that is the standard “relational data base”. The OSI Knowledge Operation System is simpler, fully
interoperable (non-proprietary from the beginning), and is grounded in a
stratified complexity paradigm based on cognitive neuroscience and the physics
of regularity as expressed at various levels of organization, including
electro-magnetic spectrum and in human
organization of personal knowledge.
The Sowa-Ballard Framework addresses such a high level of
abstraction that any sequence of events can be annotated by providing
descriptions for the elemental primitives.
However, one has to “bend one’s mind” a bit to get to the philosophical
and metaphysics import. Thus for
software development in a domain, such as the analysis of threat events, one
needs the concreteness of the Zachman Framework or sometime like the Zachman.
Another issue is about how might one derive the Zachman
form from the Sowa-Ballard form? Is
this even possible? Both of these forms
have a claim to universality. In either
case the justification is a matter of some interest.
Clearly the Sowa-Ballard Framework finds justification in
historical trends from logic and philosophy, and ultimately a theoretical
construct that Ballard has worked out (but not fully published, as yet). Ballard has been historically involved in intelligent
tutoring systems, and the modification of the earlier Sowa Framework reflects
that need to increase the set of primitives from 12 (Sowa) to 18 (Sowa-Ballard)
via the introduction of the descriptor “universal” to the Sowa enumeration {
occurrent, continuant }. This increase
added what is needed to bring the self-image of a person learning into the
framework. Universality is contrasted
with the (local and situated) occurrence of something or the continuation of
something. In this way, Ballard has
introduced a stratification principle into the 12 – primitive Sowa Framework.
The Ballard Framework is then more paradigmatically consistent, than the Sowa
Framework with the tri-level architecture for machine intelligence developed by
Prueitt.
Just as clearly, the Zachman Framework is based on the
regularity of the enumeration of six interrogatives. This is an empirical justification having some weight. The five roles, in the Zachman, does also
seem to have a universality that is observed when one starts to become
comfortable in using the Zachman.
To be complete on this issue of what are the fundamental
Frameworks, one has to note the work of Pospelov that suggests that there is a periodic table
related to the semantic primitives as expressed in languages.
The I-Ching is also a Framework whose use in “knowledge
management” goes back at least 3000 years.
The Zachman Framework takes a specific orientation towards
complex processes that are produced by the combined effects of the five roles {
planner, owner, designer, builder, subcontractor } with six
interrogatives. The interrogatives are
classical and have seen wide use in analytic methodology. If we are to consider
the intrusion detection domain we might select a different enumeration of
roles, but keep the same interrogatives as the Zachman
{ what, how, where, who, when, why }.
Some thought needs to be applied here, but perhaps the five
roles for intrusion detection are
{ social entity, controller, architect, agency,
proxy }
Of course this incident role description is the “same” as
the Zachman, except we have used terms that perhaps fit the language used by
computer emergence response teams. But the
meaning is focused and quite different.
Why/proxy is different form why/subcontractor, because proxy and
subcontractor have similarities but also differences in contextual meaning.
In developing a trending analysis of cyber events a
community can use the Incident Framework.
This methodology is quite simple and the cost of placing an Incident
Framework into deployment status is really not the issue. The issue is in communicating to the Power
That Be (PTB) the ease and value of the methodology.
The interface between the Incident Framework and the visual
rendering of categorical Abstraction (cA) will be demonstrated sometime, for
the first time, in September 2002.
A similar framework can be established for trending events
related to the examination of satellite imagery and intelligence
communications. Again, the issue is in
communicating to the PTB.
In either case, there is structural regularity in the:
1)
Textual expressions that are
used within each of the 30 primitives.
2) Co-occurrence of expression type between primitives in the case event.
This regularity promises a non-statistical predictive analysis methodology that is easy to understand by analysts working on event trending.
The
approach being suggested is in fact stratified as the decomposition of events into
substructure is done in such a fashion as to allow similarity analysis and human annotation to develop low cost, agile event knowledge bases.
Section 8: On enumeration by the human of the cell
values over an event class
Consider the
Domain space = { E l | l = 1,
. . . , 100 }
described
by 100 Frame instantiations, Fl , to produce 1900
individual data pieces
{ Fl | l = 1, . . . , 100
} à { < a(0), a(1),
a(2), . . . , a(18) > l | l = 1, . . . , 100 }
= .
Frame instantiations, Fl
, are created by completely filling out the SB-Framework’s 18 cells and 1 name
tag for each of the 100 events.
One can change the partition on the
1900 individual data pieces by categorizing the values in each cell. Remember that the cells are also called
“slots” in script theory. Over time a
slot is defined to be the “container” for the reoccurring cell values.
The notion of an autopoietic envelop
with “structural coupling” is relevant to this notion of a script (or
framework) slot. The notion of
autopoiesis was developed in 1989 in Maturana and Varela’s book “Tree of
Knowledge” and fits well within the various cognitive science and ecological
physics that we use to ground the tri-level architecture
for machine intelligence, and the physics in stratified complexity.
Over time the question becomes about
what are the values that have been entered into the slot. This question leads to a categorical
abstraction about the nature of the cell in the context of the class of event
in the domain space.
{ Fl | l = 1, . . . , 100
} à { { a(1) l },
{ a(2) l }, { a(3) l }, . . . , { a(18) l }
}
is a set of sets. Each of the “contained” sets is a set of
values occurring in a single slot.
This set of sets is more
compactly expressed as:
{ { a(i) l }
i | i = 1, . . . , 18 }.
The Sowa-Ballard Framework is considered to be more general than the Zachman Framework. But either one of these frameworks can be learned, by almost anyone, in a few hours. One gets used to thinking about “relative physical universal” as “interaction, which is the (2,1,3) cell of the Ballard Framework, for example. In using the Zachman Framework one actually has guidance from the Zachman Institute and from several published books. A clerk whose job it is to develop enumerations of frameworks simply gets good at converting tacit knowledge into what is then processed to become the designated structural coupling between events.
The process of enumerating the cell values
for 100 events might take a day or two if the human is familiar with the
events. These events can literally be
anything, individual text reports or events that have caused a crisis
management group to assemble.
The events might even be some event in
computational space, such as database accesses, and the cells might be
automatically populated by first order logics (consisting of if then
expressions) and something like a Petri net.
But we are focusing on the case where the Generalized Framework is
presented to a human as part of a knowledge elicitation process.
In the case that we have a human in the loop, we have
an extension of the model of human memory, awareness and anticipation that
Prueitt has derived from basic
research in behavioral
cognitive science. Once this model
is achieved, then one is free to use the tri-level architecture specified in
the book “Foundation of Knowledge Management”, by Prueitt, in press) and in
particular to use the minimal
voting procedure invented by Prueitt in 1996.
Section 9: Using the MVP to rout information
The instantiation of a
Sowa-Ballard framework for each of a series of events lead to a categorical
abstraction about the nature of the cell in the context of the slots of events
in the domain space
{ E
l | l = 1, . . . , 100 }
{ Fl | l = 1, . . . , 100
} à { { a(i) l }
i | i = 1, . . . , 18 }
From
each of the slots (e.g., framework cells) we create categories around those
values which are the same, or closely similar.
The issue of similarity must be formally handled with a thesaurus so
that if strings that are not equal are to be treated as equal, for the purpose
of the categorization; then this is well documented. We might reduce the size of the set of { a(i) l
} first in the very nature way in which
exact equality will reduce the size of a set.
In
doing this, one might record the frequency of the value as an occurrence in the
slot. Due to repetition, the set of
values will often be less than the number of events. One might reduce the set of categories further using a
thesaurus. The result of this process
of reduction produces categorical abstraction atoms for each slot. The notation for the categorical abstraction
atoms is made by introducing a prime symbol, so that a’(i) is used for the
derived slot atoms and a(i) is used to indicate the original cell value. It is appropriate to talk about the
reification of slot atoms.
Now,
following the original notation for the Minimal Voting Procedure we have, for each in a
series of events
Domain space = { E l | l = 1, .
. . , 100 },
The set C0 is predefined,
initially, and associated with the names of the event types.
C0 = {
a(0) l } = { a(0) l | l = 1, . . . , 100
} = {
a’(0) g | g = 1, . .
. , q < or = 100 }
Where the prime
mark “ ’ ” in a’(0) indicates that the set { a’(0) l } has been reduced using similarity
analysis (see for example the work by Prueitt on declassification similarity engine).
For each of the events we
produce a representational set for the event using a Framework, such as the
Zachman or Sowa-Ballard. For
specificity let us assume that we are using the 18-element Sowa-Ballard
Framework. Over the domain space,
assuming 100 events, we have:
Domain space à { <
a(0), a(1), a(2), . . . , a(18) > l | l = 1, . . . , 100 }
In the Minimal Voting
Procedure notation, objects
O = { O1 , O2
, . . . , Om }
can be documents, semantic passages
that are discontinuously expressed in the text of documents, or other classes
of objects, such as electromagnetic events, or the coefficients of spectral
transforms. Here we take the objects to
be events and m to be 100.
Some representational procedure
is used to compute an "observation" Dr about the events.
The subscript r is used to remind us that various types of observations are
possible and that each of these may result in a different representational set.
We use the following notion
to indicate the observation using a Sowa-Ballard Framework:
Dr : Ei
à { a(0), a(1), a(2), . . . , a(18) }
This notion is read
"the observation Dr of the event Ei produces the
representational set { a(0),
a(1), a(2), . . . , a(18) }
We now combine these event
representations to form category representations.
·
each
"observation", Dr, of the event has a "set" of
cell values
Dr : Ek
à Tk
= { a(0), a(1), a(2), .
. . , a(18) }
·
Let
A be the union of the individual event representational sets Tk.
A = È Tk.
One can talk about slot
entanglement in various ways. If S(i)
and S(j) are two slots and q is a slot atom in both slots, then a SLIP reading of the membership
records for S(i) and S(j) will produce the categoricalAbstraction atoms s(i)
and s(j) with the “relationship” between the two slots given as the slot atom
q. The SLIP parse of the data will
produce the relationship, called by Pospelov a syntagmatic unit,
< s(i), q, s(j) >
The categoricalAbstraction
(cA) and eventChemistry (eC) software products now (as of September 2002) allow
humans to easily see all of the entanglement between slots, and to annotate
meaning to this entanglement.
This set A is the
representation set for all of the slots of the framework over the domain space.
Using an iterated process, the humans in a community develop the category
representation set, T*q, is defined for each category
number q.