(Bead 3. .) Send note to Paul Prueitt . (Bead 5. .)
We ask that
comments and discussion on this series be made in the Yahoo
groups from, eventChemistry.
Generalized Framework Theory and SLIP
August 23, 2002
Look
again at the Zachman framework. Filling
in each of the cells of the framework develops a description of a
situation. See previous bead.
The
Generalized Framework (GF) has the form of an n tuple:
Event
à < situation,
a(1), a(2), . . . , a(n) > equation 1
In this case the Zachman Framework contextualizes the situation or the contextualization is about some other framework, such as a framework related to a computer intrusion event, or a distributed cyber event.
For a specific type of event,
relationship and context are almost the same notion. The cells of a framework are related by the event as in equation
1 above. Multiple events of the same
type can be described by using a common framework. Again this is done in computer intrusion event detection
systems. The Intrusion Detection System
(IDS) log file is a 1 * q framework where q is the number of columns in the log
database. The contents of the cells are
automatically written out to a log file.
One should reflect on the fact
that the content of the IDS framework cells are often populated by a function
call of some type. Different IDS have
different log files. Sometimes a cell
is left empty. For IDS log files in no
cases is the cell populated with two contents. These reflections will be picked back up in a later Generalize Theory
of Frameworks (GTF) bead. For now we
only suggest that as a human team fills out a Zachman type framework, we often
have uncertain information, information that will change over time and
incomplete information. The information
may be self-deception, or the consequence of mis-information from an
opponent.
The information at the beginning may be partial, and yet
by calling into the event knowledge base; various automated filling out of the
other cells is certainly possible.
This provides one level of predictive analysis.
We can
review previous
bead to remind ourselves that a Generalized Framework (GF) serves as the
means to categorize atoms into classes, decompose the situations into n-tuples
and rout the atoms through an associative memory mechanism. The associative memory mechanism and the
Matrix of verb forms, being developed by Don Mitchell, are related.
The SLIP
browsers take as input an ASCII file with two or more columns. Two of these columns are selected and one of
these becomes the relationship type and the other becomes the atom type.
In the
intrusion detection system log files we have no choice over how the log records
are produced.
The
first place that we have a decision is over which two columns to select from
the log file, and this is done with the SLIP Warehouse browser.
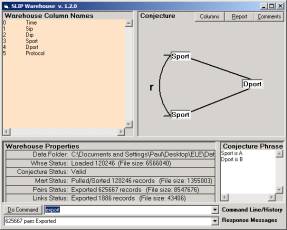
Figure 1: The SLIP Warehouse Browser
See any
of the OntologyStream tutorials.
What the
warehouse does is to develop the categorical Abstraction (cA) defined by the
link analysis conjecture. In the
classical SLIP browsers the cA are of two types, link types and atom types.
As a
generalization one can imagine having m classes of link types and n classes of
atom types:
Event à < situation(1), situation(2), . . . , situation(m),
a(1), a(2), . . . , a(n) > equation 2
But this does not match the notion of a GF. In the GF we have only one link type, but we also have n atom types (one for each cell in the framework). The link type is further sub-classed using an external taxonomy of event subtypes each event subtype “sharing” the same GF. This is an important point.
The new browsers that Don Mitchell
is working on are CLIP (Complex Link analysis, Iterated scatter-gather and
Parcelation). The CLIP technique is
defined as follows: we take GF, as input mechanisms, and convert the values in
the framework to the values in the n-tuple (equation 1).
The first value of the n-tuple is
an event type. This event type is
already known because the instance of filling out the framework identified the
event type. This is to say that a
prespecified event type as a “filler set” over the GF. This filler set is from an external
taxonomy.
Set of event
types = { situation(1), situation(2), . . . , situation(m) } equation 3
and in each case the same GF is
called up and values placed into the GF cells.
Over a period of time, one of the
situation types, say situation(k) may be repeated with some of the associated
cell values having variations. In this
case, and this case only, we begin to produce cA atoms.
These cA atoms are then processed
by the CLIP Warehouse.
When the CLIPCore Browser is opened and the data imported, the various types of category atoms are made available for the scatter-gather process (to produce higher order categories), and for visual rending of atoms and links. Each atom type is given a different color. And, because we are using GF to structure the input stream, we have only one type of “non-specific” relationship. The values that this non-specific relationship takes are from the open set in equation 3 which is a set defined in the naming of the “events” that are identified by some (un-specified) process. These events are identified in various ways, but once identified a GF is called forward and the cell values filled in (again in some un-specified fashion). This is the input stream to the event Chemistry (eC) processes.
The use of the CLIP system over
time will “learn” the event categories that provide the least amount of
un-expected clustering in the scatter-gather (stochastic) process seen in the
Core Browser.
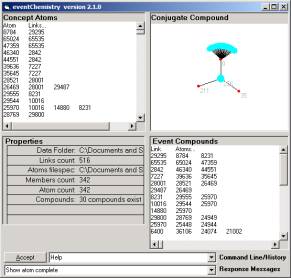
Figure 2: The Event
Chemistry view of category icons
Once this stability regime has been
found then any new clustering is really the real time detection of a new event
type. This novelty can be immediately
checked. The CLIP system can be set up
to automatically send notices on the event of an unexpected event. Several scales of invariance detection are
at work and so the unexpected event is likely to really be something new.
The stability regime is found by
reintroduction and re-definition of the situation types in equation 3 using a
simple form of evolutional programming (derived from genetic algorithms). A utility function makes adjustments so that
a mismatch signal is reduced.
(Bead 3. .) Comments
can be sent to ontologyStream e-forum . (Bead 5. .)