(Bead 2. .) Send note to Paul Prueitt . (Bead 4. .)
We ask that
comments and discussion on this series be made in the Yahoo
groups from, eventChemistry.
Generalized Framework Theory 3
August 15, 2002
The
generalized framework has the form of an n tuple:
< situation, a(1), a(2), . . . , a(n) >
Suppose we have a number of events “experienced” and each of these events are decomposed into elements, by filling in the cells of a Zachman-type framework with natural language phrases. One can take the phrases and produce an ontology that provides an interpretation of each of these phrases into elements of the ontology. This is easiest if rich machine ontology (a dictionary of terms) is available and the cells of the framework are filled primarily in terms of, or with the direct use of, terms in the machine ontology.
In the simplest case we assume the later, that the cells are almost always filled by preexisting “fillers” (to use the Schank terminology), where the fillers where already atomic elements related in a correspondence to elements of a machine ontology.
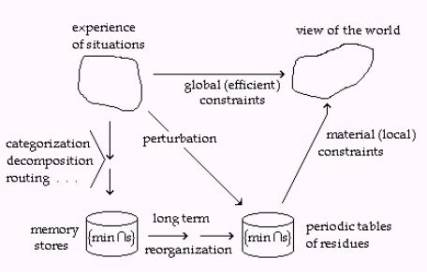
Figure 1: The process flow
model of human memory formation, storage and use.
In the more difficult case, from the technology point of view, we need to allow the user to place whatever information or designation into the cells, and then modify the ontologies and bag of fillers to adjust to the human input. The general architecture, for co-evolution of human-language-use and machine-ontology, fits within the senseMaking architecture (use IE as this is a PowerPoint presentation) developed by Prueitt in 2001, with the help of Dennis Wisnosky (Founder of Wisdom Systems).
It is natural to think of the
situational event as the relationship and the atoms as the constituents of the
relationship. Experience is then broken
down into, or decomposed, into the invariance that occurs more than one time
across the set of experienced events.
The
Generalized Framework (GF) serves as the means to categorize the atoms into
classes, decompose the situations into n-tuples and rout the atoms through an
associative memory mechanism.
As a
first step we “measure the data invariance to obtain the atoms”. This measurement
sets up the associative memory mechanism.
The associative mechanism acts on a regime of evaluative inputs (utility
function) and evolves associative linkages between atoms in various contexts. We have a type of adaptive evolution of a
measurement of invariance into data regularity in context (or we might call
this “eventChemistry”).
Suppose
that the i-th event in a collection of events is designed “E(i)”. Suppose that
E(i) is decomposed
into < situation(i), a(1), a(2),
. . . , a(n(i)) > .
Then we can “bin” the occurrences
of instances of atom types, so that
{ < situation(i), a(1), a(2), . . . , a(n(i)) > }
= { E(i) | i ranges over some
index set }
defines the set of atoms required
to be stored in the memory.
Each of these atoms/atom-types
has a set of valances to other atoms depending on various convolutions
(measurements) such as co-occurrence.
These atoms look like what we were finding using the early OSI
SLIP browsers.
(Bead 2. .) Comments
can be sent to ontologyStream e-forum . (Bead 4. .)