Saturday, August 14, 2004
On the issues of separation of
syntax and semantics pragmatics à .
Previous proposed technology evaluation à .
On forming the team
Optimal
Text Retrieval (OTR) Engine Diagram
The two sides of the
Anticipatory Web
Ken Ewell, Jim Waters and I agree that open communications with a small group of theoreticians is necessary if we are to show how PriMentia technology can be used as the data engine, and Readware placed on top of the PriMentia technology as a "provably optimal search engine with "knowledge of language". Ken has a 1989 patent covering his technology. Patents also cover Primentia’s work. So this work will become fully transparent within a small circle of information scientists. This will help in the design process and will insure that the usability of the software is optimal.
As the next design document will show (publicly), we are proposing two stages in the integration and rapid deployment of PriMentia Inc and Readware Inc technology.
1) The PriMentia patented innovation is captured in a small engine compiled in an Intel processes operating environment. This is called the Hilbert Engine ™ . This engine encodes data into what Ontologystream has called a Key-less Hash Table. Various notational papers, about the key-less hash, have been written by Ontologystream staff and published into the public domain.
2) The Readware patented innovation is captured in a small engine and in an extensive repository having “knowledge of morphological and phonetical structure” in English and in several other languages.
These two technologies can be lightly bound together within 45 days as a software package having a (Commercial Off The Shelf) COTS interface of the current Readware software. The result is an encoding of linguistic (un-structured) text into what Ontologystream staff has called Orbs (Ontology referential bases), where the Orbs are Hilbert Engine encoding having Readware services. The Readware services to the Hilbert encoding is then used to provide the same, exactly the same, query over text that Readware currently produces, but at orders of magnitude faster speeds (on the same processor). Benchmarking to the current Readware results is to be examined in a study that will be conducted and extensively peer reviewed within scientific circles and within the government agencies and consulting groups. A workshop will be convened at the 60 day point.
The workshop will have two goals:
1) Test environments will be developed at the workshop. These test environments will test the claim that the search has
a. zero complexity [1]
b. has fractal scalability over the data encoding use of real memory
c. has ontology services [2] that provide high fidelity conceptual indexing
2) Information scientists will develop auxiliary processes that manipulate the underlying Orb constructions and the Readware Ontology Base.
a. In Sowa and Majumdar’s paper “Analogical Reasoning” the case is laid out that both a formative process, “structure mapping function” Falkenheimer, Forbus and Gentner (1989) and a “ high-level perceptual function” is involved in the emergence of reasoning and thought in the human mind. These two function correspond to the role of memory of invariance (cA) and anticipatory responses (eC) as specified in the tri-level architecture. The development of tri-level architecture to support Orb based reasoning mechanisms can be addressed after the Readware software is tightly linked with the PriMentia data encoding. (more will be said on this in the next bead [67].) It is noted that Sowa and Majumda already have a functional software system that combines the two functions. However, we have not talked about how if the VivoMind engine might relate to the Hilbert encoding.
One must point out that an open design process involving several first-rate information scientists and open source code is not the norm in today’s secretive and proprietary software industry.
As will be demonstrated, the new Human-centric Information Production (HIP) software paradigm is protected by patents, are made available at a “reasonable cost” [3], and will be explained in clear and easy to understand language.
The description will join the textual elements of the BCNGroup’s Bead Game. The beads are textual representation of our scholarly discussion. This textual discussion is part of a distributed scholarly discussion about how to provide a next generation technology in the simplest and most powerful form. The conceptual index into the set of textual description is at:
The integration will be open source code, C and Python unless we see why something else would be used. The architecture will be independent of anything but FTC/IP and some type of peer engine based on concepts that reflect some minimal CoreTalk design principles. The dependencies on J-BOSS and .Net create instability in software code because of the vendor strategies for both incremental marketing and up-grades. No such dependencies will exist for us.
In the 90 day period, we will give the full innovations completely and with very clear notational foundation and open source code (with the exception being very small engines that are part of the technology offered to the community by PriMentia and Readware.) If this new capability is deemed worthy, then the government and other entities may license the technology for use in projects that they might find important.
Once the integration of the PriMentia engine and the Readware technology has been accomplished, we will be able to show that the underlying Orb constructions can be manipulated using data mining process that are described in the Orb notational paper.
The architecture that we are defining (see beads [67] and [68] etc..) allows the underlying Hilbert encoding to be manipulated directly through what will be a very simple set of API calls. This calls are essential a simple file open and file close, or pipes between the data encoding and a set of mathematically defined transformation called convolutions.
.
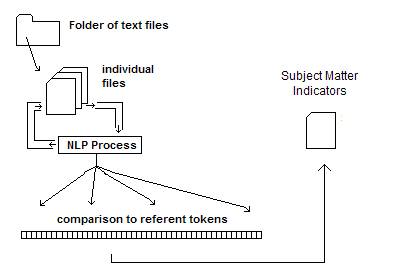
Optimal Text Retrieval (OTR) engine [68]
The Orb technology can be used to develop taxonomy and ontology based on the identification of patterns of word occurrences: see: bead thread on InORB Technologies.
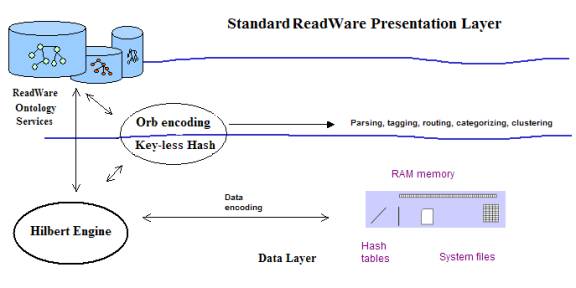
Another look at the data layer is given in the following figure:
Orb encoding using a key-less hash table
Readware performs the National Language Processing (NLP). The Hilbert Engine ™. Performs data encoding into the key-less hash table. Data mining processes will produce Subject Matter Indicators and will automate the development of controlled vocabularies that enhance knowledge management within communities of practice to enhance retrieve form the index of concepts found using the Readware retrieval.