ORB Visualization
(soon)

The 1998 FCC
Public ORB
Preliminary look
November 27, 2003
A machine dictionary/thesaurus//ontology
is developed from a collection of Subject Matter Indictor neighborhoods. The
neighborhoods are small parts of a graph indicating the co-occurrence of “near”
words (see Figure 6 – 8 below for examples).
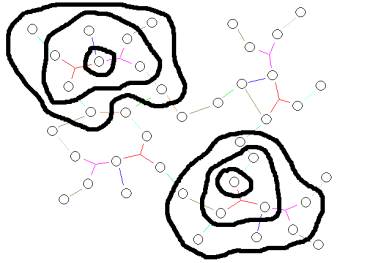
Figure 1: Part of the co-occurrence graph with two identified
Indicators
In Figure one we
illustrate two of the Subject Matter Indicator neighborhoods.
The ORB international algorithms are based on a word level
“n-gram” over the significant words within the text of a collection of text
(See Figure 1 below). “Structural”
relationships are produced autonomously.
These structural relationships are then indicative of semantic
interpretations that can be made by a human when reading the text.
Ontology Referential Base provide a means to bootstrap into a
set of profiles, based on key words, where the key words are those that have
been determined by the words in the Subject Matter Indicator
neighborhoods.
A conceptual map of a significant part of the subject content in
the collection of text is thus made available for high precision/recall
search.
Human
experts need to take a few steps to confirm/refine Subject Matter Indicator
neighborhood profiles generated by the system. However, this confirm/refine process
is easy to accomplish when one is knowledgeable about the subject matter. Both at top down, and a bottom up
methodology is used to select a small percentage of Subject Matter Indicators
and express them as Fixed Upper Taxonomy.
A full text
index engine, from Instant Index Inc., is given the contents of a Subject
Matter Indicator neighborhood from this Upper Taxonomy. The Upper Taxonomy serves as a
"controlled vocabulary" to produce high fidelity conceptual recall
supporting public research on the FCC publications.
The 1998 FCC ORB
Steps we take to develop the 1998 FCC ORB included preprocessing of the 3,667 text elements to reduce the content to a date and sentences. This will lose some subject materials, header and other non-sentence structure, but these can be re-obtained when we use a full text query to acquire original text.
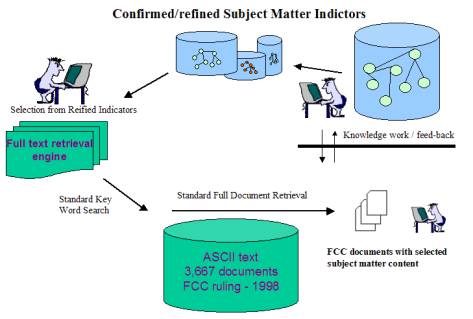
Figure 2: Full Life Cycle production of search elements
A Visual Text tool reduced each FCC document to a new document having only good complete sentences). The reduced to sentences FCC documents support the NdCore conceptual roll-up and the experimental ORB system.
The experimental system licenses the ATS CCM patent and follows the ORB notational paper. A diagram of the core process is seen in Figure 3.
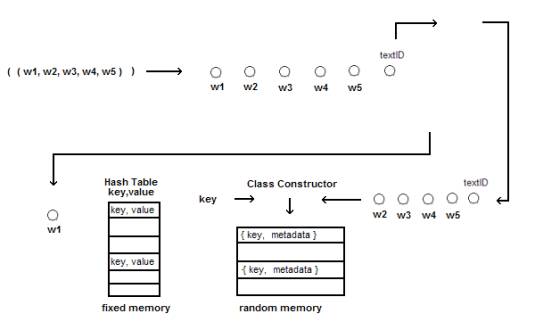
Figure 3: A core process involved in developing the Subject Matter Indicator neighborhoods from an analysis of the text.
In Figure 3 we show the architecture in which frames gather together the co-occurrence of words into a collection of relationships having the form < a, r, b > where a and b are words and r is the relationship of a and b occurring within a sentence. Simple link analysis then leads directly to the Subject Matter Indicator neighborhoods in a graphical constructions which is the graph representation of the set { <a, r, b> } gathered over the entire text corpus.
Two things are important in making this work as well as it does.
1) a categorical reduction where multiple instances of relationships of this type are treated as a category (i.e. as one thing rather than as many occurrences of the same thing)
2) the linguist pre-processing provides modules that find noun, verbs, noun phrases, verb phrases; and sentence boundaries. This cleans up and presents to the core process the best material indicative of subject matter.
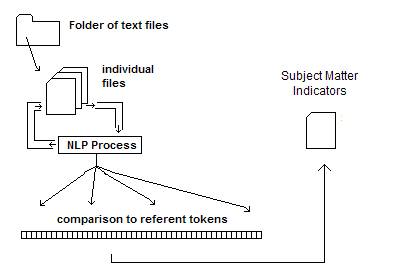
Figure 4: Illustration of the role of Natural Language Processing as a pre-processor
The resulting data warehouse for the 1998 FCC rulings is remarkable in its elegance. The ASCII file is 2,537 K (811K compressed).
This is the only data needed to representing "all" concepts expressed literally by the documents published in 1998 by the FCC into the e-DOC repository.
www.zippedTestCollections/1998FCC.zip
Any one can use this to develop the 1998 FCC ORB. Follow the tutorials.
Images from the ORB
Figure 5 shows a complete retrieval of all 12,562 concepts.
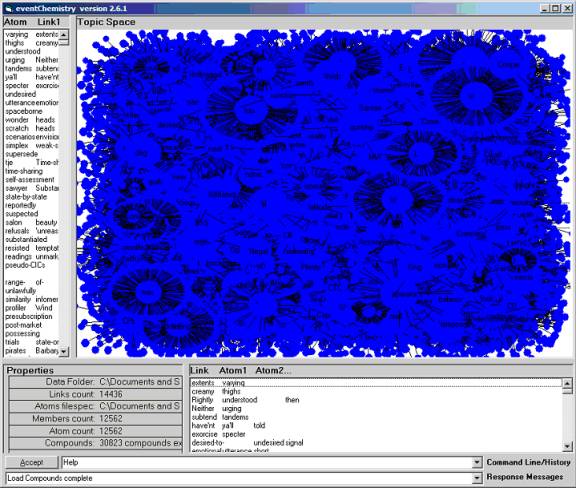
Figure 5: 12,562 concept atoms in the “complete 1998 ORB
Figures 6 – 8 show three examples from the 1998 FCC ORB.
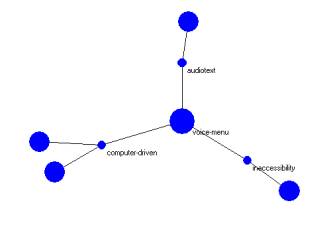
Figure 6: The voice-menu atom
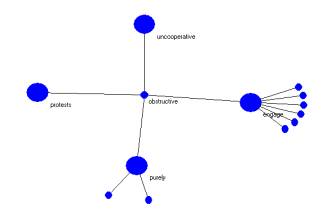
Figure 7: The obstructive atom
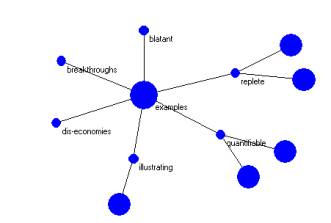
Figure 8: The examples atom
Some things to think about
There are a number of things to talk about.
First we note that the entire ORB is almost fully connected into one graph. Some extension of the software will easily provide a selective attention into part of this large graph and to let “most” of the graph structure to fall away.
1) Can one use a sentence spoken, or typed, by an individual to retrieve only those compounds (compounds are larger than neighborhoods) that are specific to the words used in the spoken sentence?
Answer
is yes of course.
2) One can identify the "stop words" that will fracture the complete graph into primes. We can now do this over in FoxPro and then rebuild the datawh.txt file from which the SLIP browsers will quickly produce the fractured structure. (This is this weekend’s project.)
3) #2is similar in method in the currently deployed NdCore conceptual roll-up system where the largest structures of NdCore are removed before the metaconcepts are generated.
4) We need the get also the infrequently occurring compounds and remove all or most of them. We know how to create a resolution operator on the ORB so that things that are not occurring at a certain frequency will not be seen. Right now this frequency parameter is hard wired in the SLIP browsers, but when funding arrives OntologyStream can re-engage Don Mitchell to produce this differential resolution.
The result of doing #4 is the production of a metaconcept level that is a quick and complete view of the larger structure – producing a classical two level Broad-term / Narrow-term taxonomy.
SLIPCORE takes 34,220K in developing the ORB constructions. However, the data structure once completed takes less the 7,000K.
The entire ORB fully expanded in memory takes less than 25,000K. At this point the retrieval of any single Subject Matter Indicator neighborhood (Figures 6 - 8) is literally less than 20 machine cycles. Rendering of the image is then “instantaneous.”
But the eventChemistry browser (SLIPEvents.exe) seen in Figure 5 is taking 818K of memory when the browser is not the active window. When active it is 1,402K. Retrieving a new atom (by clicking in the links or atoms list) maps out 5,620 K in memory and then renders (in less then 1/10 second). From that point – until the memory is released and the browser goes back to 1,402 in memory use, the retrieval is instantaneous (again – I think that this is less that 10 machine cycles plus the drawing routines.)