First Report on eventChemistry
™
Paul S. Prueitt,
PhD
Founder (2001), OntologyStream
Inc.
Monday, December 17, 2001
First Report on eventChemistry
™
OntologyStream
Inc.
Monday, December 17, 2001
Overview
OSI is looking for partners and/or benefactors in each of these five vertical markets.
OSI’s eventChemistry ™ integrates two types of computer science. Sensor Linking, Iteration and Parcelation (SLIP) is implemented using a In-Memory Referential Information Base (I-RIB). I-RIB provides speed, format interoperability, and compact mobile engines for SLIP algorithms.
Event chemistry uses a diffusion aggregation computation to form event (or instance) maps. In each vertical market the user community can evolve slight variations of the event chemistry. Sharing of event chemistry requires a vertical specific OSI Enterprise Solution.
Section 1: Status and Progress Report
SLIP principles have now been applied in different domains. The basic algorithms and theory are public domain.
Domain knowledge is not only vital to evaluation but also to final domain specific interface design. This has always been the case with horizontal technology. In each application area, a major effort must be made to develop user tools and the user interface. The enterprise software development requirement provides the primary Return On Investment to OSI Investors and Board Members. A vertical enterprise implementation will generally cost at least $150,000 and take 3 to 4 months.
December 1st, 2001, OSI made an internal commitment to complete the still unfinished Event Browser. We decided to extend the use of In-memory Referential Information Bases (I-RIBs) in the development of .NET-type object model to support any type of event chemistry. This new work provides an deep innovation based on diffusion-aggregation methods.
A small (< 50K) operating shell was developed to have all properties that are shared in common with the three SLIP Browsers. This small operating shell is called the Root_KOS. Root_KOS is being developed to have a voice gesture controller and both a PDA interface and Internet browser interface.
By December 5th, 2001 OSI had generalized the model for event log analysis and made these generalization available in the SLIP Warehouse and SLIP Technology Browsers. On December 7th, an exercise on importing an arbitrary event log was made available.
We applied our technology to a raw FTP log from a Linux web server. Software Systems International (SSI) provided the data set. Our study showed that linking senor probes, placed in host machines, can autonomously generate generic vulnerability assessments. As these vulnerability assessments are completed, hacker activity can be anticipated and either blocked or diverted. SSI’s CylantSecure measures software behavior and controls access to critical behavioral regions related to hacker vulnerability. Cylant Secure complements the use of Intrusion Detection System (IDS) audit logs, such as those from RealSecure. OSI’s technology allows a visual interface to control IDS systems.
Beginning on December 15th, a preprocessing module was developed to examine the thematic linkage between elements in a text database. The application domain of primary interest is telecommunications trouble ticket analysis and trending analysis of hardware failures.
SLIP was initially based on shallow link analysis. The term "Sensor" replaced the term "Shallow" on December 10th, 2001. On December 18 the acronym was shortened again. The new data mining technology started to be referred to as Sensor Linking, Iteration and Parcelation (or SLIP). With this change in designation can an understanding of a data fusion solution based on I-RIB data format.
Section 2: Event
Browsers and eventChemistry ™
Human analysis based on the viewing of event chemistry is predictive in
three ways
1) The human has a cognitive aid for thinking
about and talking with peers about the events and event types
2) A top down
expectancy is provided for pattern completion of partially developed event
chemistry
3) Coherency
test separates viewpoints into distinct graphic pictures and this provides
informational transparency with a selective attention directed by user voice
commands.
OSI’s data mining technology is based on link analysis, emergent
computing and category theory. SLIP and
I-RIB technology provides ready to use data mining and data visualization
tools.
·
Both atoms and
links are abstractions taken from the actual data invariance that exist in the
data source. The data source is any
event audit.
·
Automated conversion
of event chemistry to finite state transition models (colored Petri nets) is
possible. This conversion will push
automation from the Browsers into an Intrusion Detection System (IDS) or any
Distributed Event Detection System (DEDS).
·
A theory of
state transition and behavioral analysis is available and is to be applied (by
OSI) to creating templated profiles of hacker activity and intentions.
·
The work on
modeling hacker intentions is to be generalized to models of criminal and
terrorism activity.
A critical issue has to do with the prediction of events before they
occur and/or the identification of an event while the event is occurring.
The Event Browser works with two layers of event chemistry in
correspondence to event atoms and event compounds. Event atoms are simply the data invariance that exists in a
two-column data construction derived from the Analytic Conjecture. Each of the atoms has one or more associated
valance types. Valance types are
abstractions that correspond to the service link defined in the
Conjecture.
Event chemistry is an diffusion-aggregation process that finds a
resolution to event atom valance. This
leads to the new event chemistries.
Section 3: Future developments
In early December 2001, Don Mitchell, at Cedar tree Software, and
Prueitt spent a few days talking about the computer science based on .NET
Visual Basic and C# and theoretical work based on a model of diffusion
processes. The notes from this
discussion are available in the first exercise on the event browser (part 2).
A partnership between Cedar tree Software and OSI was created on
December 15th, 2001.
An
academic collaboration has been created with Dr. Cameron Jones at the
School of Mathematical Sciences, Swinburne University of Technology in
Australia.
Jones is interested in exploring the
microphysics of information packet distribution in databases. A number of data transformations show both
discrete and diffuse properties that are expressible as thermodynamics of
information packet distributions. It
was seen that the emergence of stable and transient events results in a
two-valued interpretive possibilities (the event itself, or the object space(s)
before and after). Emergence has either
occurred or it has not.
Event Chemistry is then, in a most general
fashion, defined as a process that results in the emergence of an event object
from the local properties of event atoms and atom valance. Excellent possibilities exist that current
or potential theories from cosmology and thermodynamics can be used to support
the new field of event chemistry.
Jones and Prueitt have adopted a microphysics
approach. They treat information (from
databases) as just elements of some integrated system. The premise is defined that micro-macro
correlations exist - i.e. set-limited distributions. The whole point of the database clustering becomes quite
clear. The microphysics is resolved
into a pictorial graph. Microphysical
information is encoded from the SLIP Conjecture and then specific thermodynamic
laws are applied iteratively to information packet distributions.
Dr. Jones has noted that by looking at the
thermodynamics of the process of information aggregation and dis-aggregation,
one can measure the *energy* with which the process shows elements of
self-organization. This process is
often linked with the term “fractal”, where with respect to databases (or
information). The scaling property is
strictly self-affine (since non-infinite conditions, and a stationary
signal/range-limited distribution).
The OSI eventChemistry ™ will combine local
escapement dynamics, encoded as atom and valance properties, with dissipative
rules to produce periodic excite/relax visualization. However, in some cases, the resolution is simply
under-constrained.
In some cases, complexity analysis will
indicate multiple possible event resolutions in 3 dimensions. Theory suggests that there is a minimal
dimension where an object space of that dimension is required to uniquely
resolve the ambiguities. Visual acuity
can control a cycle that seeks to resolve the event graph.
OSI and its partners are formalizing
Information Technology mining/linkage analysis after biological or chemical
organization metaphors.
Once the SLIP browsers are in place, one can
use aggregation models to define and test significant theories of interaction
between fundamental units. These models
are physical or relational, and will accept new theories to account for
development/emergence of event graphs.
Power-law persistence and patchiness metrics will show emergent
properties and yet another way to describe the discovered phenomena.
Process model for Market Development: OSI plans to make available an Enterprise System for each of several
vertical markets. We expect to derive
significant revenues from the development of these Enterprise Systems.
The OSI Enterprise System will push small mobile automation controllers
(stand-alone programs) from the desktop into Distributed components. A
knowledge base will be added. Any one
of several enterprise knowledge sharing systems are readily deployable along
with the SLIP-I-RIB technology.
The problem is not in having needed technology and software development
capability. The problem is in
management deployment in Industries that are often resilient to change.
OSI has long had an interest in
developing a SW-CMM type compliance model for the adoption of knowledge
technologies. In 1990, SW-CMM was put
forward as a Business Process Re-engineering type model to govern government
procurement of software. This model has
evolved to where it now governs quite a lot of the Federal government’s
acquisition of software and software consulting services.
A process model for OSI deployment has been under development for over
two years. The process model is simpler than the SW-CMM model for software
procurement, and reflects modern Knowledge Management practices, developed at
George Washington University and by several leading process theorists.
Section 4: The first concept maps
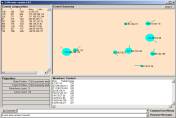
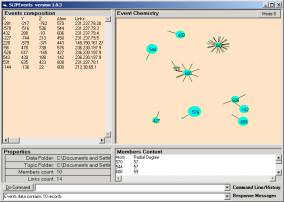
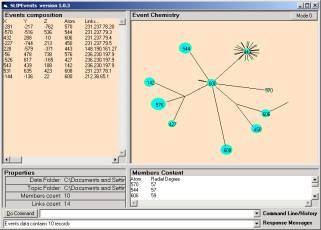
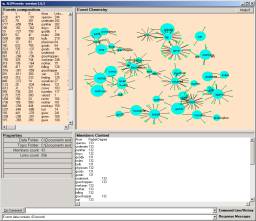
The Event Brower scatters the atoms from a category into an object space. This space can be rendered in various ways. The first iteration of object space rendering is shown in Figure 2. These rendering where produced on December 15th, 2001.
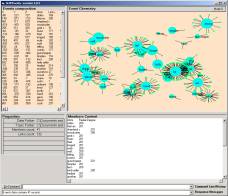
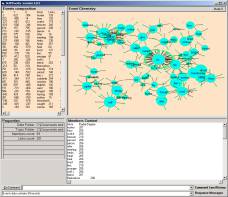
Figure 2: The first rendering of atom objects in the SLIP Object Space
Understanding this first rendering might be helpful in planning how final event chemistry is to be imposed on the objects in the space and then how the results of the chemistry is to be rendered. Let us start with the data source in the form of a file called datawh.txt. By downloading the zip file, ecI.zip, one can examine a datawh.txt file that has 2,918 records.
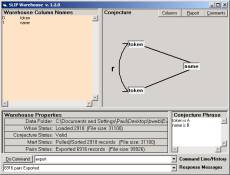
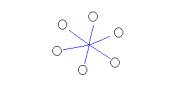
Figure 3: The Analytic Conjecture for the Fable Collection
The first of the two columns has token values and the second column has a name of one of the 332 short stories. Token values are just commonly occurring words. IN Section 2.1 we will examine the issues related to the use of commonly occurring words as indicators of meaning in text.
After unzipping ecI.zip remove all contents of the Data Folder except for datawh.txt. Then launch the Warehouse Browser and enter the following commands: a = 1; b = 0; pull; export. These four commands will produce Figure 3.
Section 4.1 Fable Arithmetic
The development of the fable collection goes back to 1996 when Prueitt suggested that any autonomous declassification system would have to be capable of doing what he referred to as fable arithmetic. He pointed out that the mosaic effect would reveal hidden relationships and provide access to declassified concepts.
Fable arithmetic exists if we have a formal system that is able to add or subtract fables and produce a fable. The addition of two fables would have to be a fable that has all of the concepts that are present in the two fables, and is about of the same size. The new story would be judged, by a child, as being an Aesop fable. The subtraction of one fable from another fable would have to have all of the concepts of the first fable except those concepts that exists in the second fable. No new concepts could be added and yet the fable should be of the proper size and pass for a fable in the eyes of a child.
Well, of course such a system does not yet exist. In 2000, Prueitt began a conversation with M-CAM Inc (www.m-cam.com) over the possibility of annotating patents and patent applications through an automated means. One technology that almost does this is the Dr. Link technology that was at the time available from TextWise Inc and Manning and Naplier Information Systems. Dr. Liz Liddy (Syracuse University) developed a system for text analysis based on Peircean graphs and linguistic analysis. Several other systems were available, the most important of which was the Oracle ConText engine purchased by Oracle from Artificial Linguistic in about 1989. All of these systems have not survived the attention span of the marketing community, in spite of capabilities that are clearly needed by intelligence analysts.
Linguistic analysis of text using deep case grammar is clearly the best technology basis for autonomous rendering of the concepts in text. The second best technology is clearly latent semantic indexing. Then comes statistical word frequency analysis, which unfortunately is the most popular technology. Under a tutored hand, n-gram analysis can out perform statistical word frequency analysis.
Autonomy Inc and N-Corp Inc have proved that a profile-based push-pull information technology can make an impact in the marketplace. Expectations from Autonomy clients soared in 1999 and 2000, only to collapse in 2001. The problem has been that the core of the Autonomy engine is based on statistical word frequency analysis. Given any one of the better technologies for rendering concepts, the Autonomy system’s performance would increase. Of course this is a OSI claim that has not been demonstrated experimentally. However we have proposed a process for making such experimental determinations.
One more issue should be mentioned. OSI claims that the voting
procedure will out-perform the Autonomy engine. This procedure is based on Russian quasi-axiomatic-logic and the
semiotic theory of reflective control, and is exceedingly simple. The voting procedure has also been used in a
prototype of a distance
learning system developed and reviewed by the State Department in 1998.
Section 4.2: The Technology Browser
After a brief diversion into the issue of how to represent the meaning of text, we can now return to the use of the SLIP Technology.
By looking at the properties window of the Warehouse Browser we can see that 6916 pairs of tokens are placed into a file called “Paired.txt”. This file is located in the Data Folder. These 6916 pairs are developed using a combinatorial program.
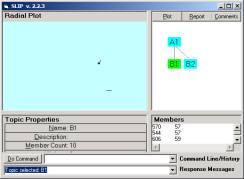
On launching the Technology Browser the user will see only the A1 category node and nothing in the Radial Plot window. To import the Paired.txt and extract atoms from a parse of the Paired.txt file, we use the following two commands:
Import
Extract
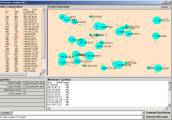
in the command line. Then the user may select the A1 node to see the randomly scattered atoms to the circle. Now type “cluster 30”. You will see that the distribution very rapidly moves to a spike. Let us look at this a bit closer. Type “cluster 200” to iterate the gather algorithm 200,000 times. You will see that all of the atoms are linked, and will move to a single spike (See Figure 4a)
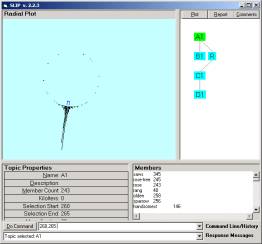
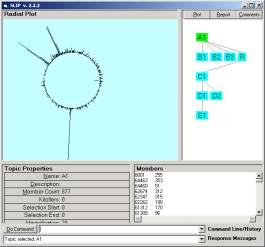
a
b
Figure 4: A comparison of different kinds of limiting distributions
In Figure 4b we show a limiting distribution from the study of Intrusion Detection System audit logs.
The phenomena that all atoms move to the same location are an indication of a characteristic of a data set developed from the fable collection. In the foundational theorems of the SLIP theory, this phenomenon is seen as due to the category of all atoms being “prime” with respect to the Analytic Conjecture (see Figure 3). The interpretation is that the fables have highly interrelated concepts, which is of course true.
From the study of other data sets, one might realize that having only one prime is initially disappointing since multiple primes indicates multiple different characteristics of the data invariance. Fortunately we have some theorems on how to “fracture a prime” and produce substructure.
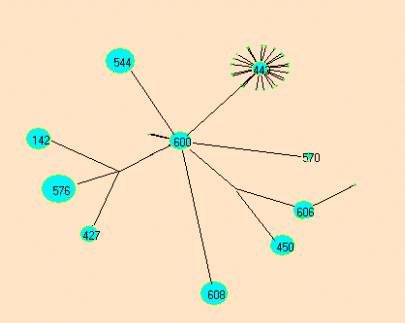
A close inspection of Figure 4a shows how this is done. We bracket out the center of the spike and put this center into the Category B1. We then use “Residue” command to put everything else in the category R. Given that we have removed the core connectivity of the conceptual linkage we now have the possibility of identifying a small but well-defined prime within the residue.
The user can randomize the A1 category (this should be the only category you have in your SLIP Framework). Just start the cluster process by typing “cluster 10”. If this is not sufficient, then enter “cluster 10” again until you have a cluster that is like Figure 4a. It might be better the catch the gather process early so that the spike is not so well formed. Now take 5 – 10 degrees out of the middle by typing
“x, y” to bracket the region
“x, y -> B1” to bring these atoms into category B1
Typing in a single degree value, between 0 and 360, will draw a red line from the origin to the circumference pointing at that degree.
Now click on the node A1 and type “residue” in the command line. This will produce the R category.
Now randomize the R category by typing “random”. Cluster just a bit to find a new small cluster. You are looking for a cluster with between 10 – 50 atoms that forms a well-defined spike.
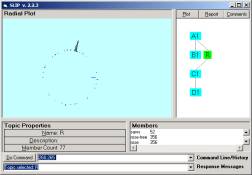
Figure 5: A well-defined spike in the residue
The user might try several times to get a small prime. Starting over is possible by closing the Browsers and copying the folder with the Browser and the Data folder and then deleting the A1 folder. One then needs to re-import the Paired.txt and extract the atoms.
Taking the spike forms C1. Use the indicator command. C1 may have atoms that are not closely related to the main body and so we may re-cluster C1 and move the spike into D1.
a b
Figure 6: Random scatter into the Object Space of D1
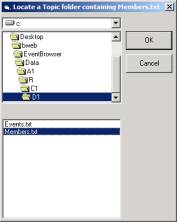
Once any node has been defined we may launch the Event Browser to look at that node’s atoms and event chemistry. In Figure 6b, we see randomly scattered atoms from category D1.
Launching the Event Browser requires that we locate the Members.txt file that is inside the folder corresponding to the node we wish to look into. In future versions the Event Browser will be launched from the Technology browser and this file selection will be automatic.
Figure 7: Random scatter into the Object Space of F1