The Functional Load of a
Concept
Copyright (2002)
This Foundational Paper is Intellectual Property of Dr. Paul Prueitt
February 4, 2002
Consider a set of concepts,
C = { ci }
where the index i is from the integer 1 to the integer n. Consider that we have a procedure for guessing if a specific concept, ci , is expressed in tk , where
{
tk } = T
is a set of text elements and k is a second index.
Select { di } = D , a subset of C , to be the “organizing set”. Now for each d* in D find all ci in C such that m( ci , d* ) < q . The metric function m is any distance or closeness function.
The neighborhood of d* is defined to be:
Nd* { ci | ci in C and m( ci , d* ) < q }
The notion of a neighborhood
is an elementary notion from mathematical topology. For example if one was dealing with a set of integers, say I = {
1, 2, 3, 4, 5, 6, 7} and q = 2, then N4 = { 3, 4, 5 }.
For integers, the metric function is easy and well defined.
Section 1: The parsing rule
For concept representations, the metric function is not well defined. However one can build a rule which one takes as standing in for a metric. In fact, one can make this “standing-in-for” simple by a technical rule that determines a yes/no answer to the question of relationship.
m( ci , d* ) < q if and only if ci and d* are related in some specific formal fashion
There are many interesting and useful rules. One that we have used is a rule that allows nouns and verbs to stand in for the concepts:
C = { nouns that appear in the text } union { verbs that appear in the text }
D = { verbs that appear in the text }
m( ci , d* ) < q if and only if ci and d* both appear in a single sentence
Once one has the two sets C and D, then the text can be parsed to determine when the condition m( ci , d* ) < q holds.
· Define a set of pairs { ( ci , dj ) } where ever m( ci , d* ) < q .
· Create a tab-delimited line in an ASCII text file for each pair.
The ASCII file plays the role of an event log where the events are the identification of the co-occurrence of a verb in the list of verbs, and a noun in the list of nouns. Sentences are examined one at a time and the event log appended when the condition m( ci , d* ) < q holds.
Section 2: The conjecture
Import this event log into the SLIP Data-warehouse Browser. The Browser’s import process develops an in memory structure that we call structural holonomy. The structural holonomy is required for fast stochastic processing. The details of how this works can be discussed under non-disclosure.
The import itself is also fast, and once completed the user can develop either one of the two possible analytic conjectures. The introduction tutorial on SLIP explains what the conjectures are. If the import file has more than two columns then any two of the columns can be selected (in either one of two ways) to produce a different analytic conjecture.
Any first order predicate logic, defined over the set of columns types, can be used to produce an analytic conjecture. The conjecture makes sense of an event log. Moreover, the event log can be produced in various ways. So the development of categorical abstraction has the two phases:
· Instrumentation and sensor definition that produces an event log file
· The conjecture
Once produced, the output data will be in the form of ordered triples
<
a1 , r, a2 >
In the simplest form of an analytic conjecture, two values from the first column, designated in the Figure as a1 and a2 , are paired if the associated value, designated in the Figure as b, in the second column is the same.
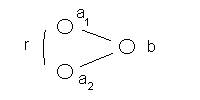
Figure 1: The non-specific
relationship between the atom a1 and a2
Formally we have:
( a1 , b ) + ( a2
, b ) à < a1 , r, a2 >
where r is the non-specific relationship. This non-specific relationship is used in the stochastic process, specifically a type of scatter-gather, provided by the SLIP Technology Browser.
At this point, we have information at two levels. The first level is the raw data linked by the non-specific relationships. The second level is a set of abstractions that represent invariance exposed by the non-specific relationship.
The non-specific
relationship is used to produce an emergent metric over the data invariance
using a stochastic process. The
pair-wise metric, when convolved via a stochastic process, is an open inference about structural
characteristics of the events that “cause” the data. In text understanding applications we find that these causes are
the thematic consistency of written materials.
We integrate stochastic convolution over the entire collection to produce a limiting distribution to the stochastic process. The local pair-wise metric is transferred to a topology on the set of all abstractions (atoms, links and compounds).
The b value
induces both a non-specific and a specific relationship. In stratified theory, the non-specific
relationship and the specific relationship are not the same. The non-specific relationship is used to
induce a global sense of what is close to what. The specific relationship is a local relationship.
( a1 , b ) + ( a2 , b ) à < a1 , b, a2 >
One way to specify a metric function is to check for co-occurrence, within the same sentence, of a noun with any verb, or a verb with any noun.
In producing the data in our introduction tutorial on SLIP, our parsing program outputs the statement;
m( ci , d* ) < q
if and only if the concept ci , d* both are judged to be present in the same sentence.
The set of concepts can be defined to be the union of the set of nouns and that set of verbs found in a text collection. This is what was done in the study of the concept functional load in the 312 Aesop fables.
Section 3: Functional
load
The set of pairs produced from a conjecture defines a set of abstractions called atoms and a set of abstractions called links. The stochastic process produces a third set of abstractions called compounds. In this section we show some of out internal notation regarding these concepts.
Let
S = { < aj , r, ai > }
be the set of all pairs of the first column elements that have a non-specific relationship, r, between the pair ( aj , ai )
Let
A = { ai | ai appears as either the first or the third part of the elements of the set S }
and let
L = { b | b appears as second part of the elements of the set S }
A is the set of atoms and L is the set of links.
These are abstractions, similar in nature to other useful abstractions such as the counting numbers or the periodic table from physical chemistry. As has been noted, such set of atoms and pairs can be derived any time we have a set of ordered triples { < aj , r, ai > }.
We can, now, address functional load in a crisp and independent fashion. We can define the functional load for either an atom or a link.
Let
Ar = { ai | ai appears as either the first or the third part of those elements of the set S that have r as the specific relationship }.
Ar is defined as the functional load of the
link r .
Let
La = { r | r appears as the second part of those elements of the set S that have a as the either the first or the third part of that element }.
La is defined as the functional load of the
atom a.
The process of mapping the functional load of concepts as expressed in text is a specific application of a more general data mining and information development. This process relies on co-occurrence of patterns.
Comments to: OSI
Chantilly VA