Index .
Automated
Citation Indexing of Text Archives
Copyright (2002)
This Foundational Paper is Intellectual Property of Dr. Paul Prueitt
and Don
Mitchell
It is dedicated to Catherine Prueitt, on her 18th
birthday (2-11-2002)
March
28, 2002
Electronic version at http://www.ontologystream.com/cA/tutorials/citationIndex.htm
Introduction
Our tutorial on automated citation develops the notion of automated citation indexing of arbitrary natural language based text archives.
One application domain is the Patent and Trade Mark (PTO) database of patents.
It is proposed that categorical abstraction can be developed to span the large and small-scale trends in Intellectual Property disclosure as recorded and adjudicated by the PTO.
We also have proposed, as part of the BCNGroup activity, an application of categorical abstraction for modeling innovation adoption as deployed technology. The specifics are discussed under non-disclosure only.
The software necessary to do primary research on linguistic functional load was made available to a small number of parties starting in January 2002.
Our data set for illustrating automated indexing is the collection of 312 Aesop fables. The complete collection is available at our research site. 312 URLs have the name:
( http://www.ontologystream.com/IRRTest/fables/BEADn.HTM )
where “n” is an integer from 1 to 312. This integer is used in the tutorial and will allow a researcher to look at the fable indexed. The first three fables at (1), (2), and (3).
Section 1: The map of linguistic functional load
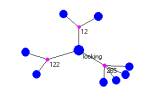
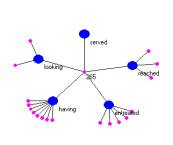
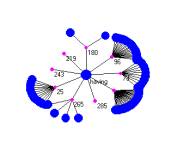
In Figure 1 we show two maps that provide a structural index involving verb use in the fables. A semantic index based on generalized Latent Semantic Indexing will produce various concept based structural indices.
a b
Figure 1: conceptMaps indexing fable 265 (a) and the concept of “having” (b)
The numbers in Figure 1 point to specific fables. For example fable #265 is The Peasant and the Apple-Tree.
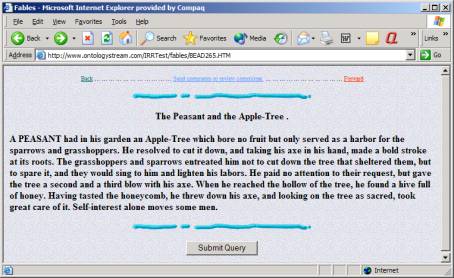
Figure 2: The URL at OSI with the 265th fable
One can find the verbs { served, looking, having, entreated, reached } contained within the fable.
Section 2: The tutorial
This tutorial is a brief instruction on how to create and view the data structure produced from in a small 22K Datawh.txt (data warehouse) found in the Data folder in the downloaded software. A profound theory of information acquisition and new computer science is hidden behind a computer interface called root_KOS. KOS stands for Knowledge Operating System.
Create a new empty folder anywhere and un-zip the software into this folder. You will see the contents shown in Figure 3. There is no install process required, as the software has no dynamic link library dependencies.
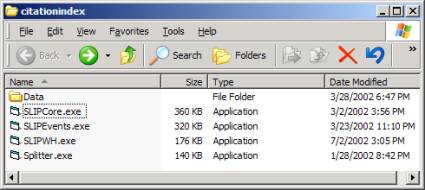
Figure 3: The contents of citationIndex.zip
Splitter is used to take a random sample of a data source. We will not use Splitter in this exercise. However, the Splitter is also designed to parse arbitrary text collections and develop datawh.txt files from any theory of word type.
Open (double-click on the SLIPWH.exe) the SLIP Warehouse browser. You will see Figure 4a. Issue the commands “a = 1” and “b = 2”, by typing into the command line. This develops the simplest form of the class of analytic conjectures.
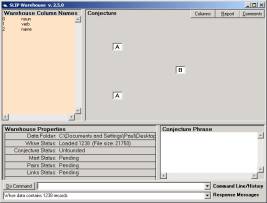
a
b
Figure 4: The SLIP Warehouse Browser
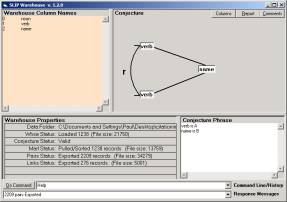
After specifying the conjecture, issue the commands pull and export. Pull is a command that asks the KOS Interpreter to pull a new data structure using only the two columns identified in the conjecture. This data structure is converted into a structural holonomy. Export builds a special data structure composed of a set
S = { < aj , r, ai > }
of ordered triples produced from the conjecture.
These data structures are written to a file that can be imported by the SLIPCore browser.
Once you have issued the four commands to the Warehouse browser, open the SLIPCore.exe file. Warning, one has to have first used the Warehouse Browser to produce ASCII files that are needed by the SLIPCore.
As in all of the OSI browsers one may issue help command to see the functions and commands available from that browser.
Once the SLIPCore opens one needs to issue commands to build the Citation Knowledge Base (CKB). The CKB is actually a virtual construction. Specific elements of the CKB only come into being as one navigates individual images. The rendering of the CKB is made in a just in time fashion. Double clicking on the AI node enables the rendering process.
In addition to the CKB, a radial plot and a classic scatter gather (stochastic) process is available from the SLIPCore. In later tutorials we will use this stochastic process to produce a SLIP Framework based on emergent clustering.
If the knowledge base already exists, then the Core browser will address this knowledge base on start-up only by using the Load command.

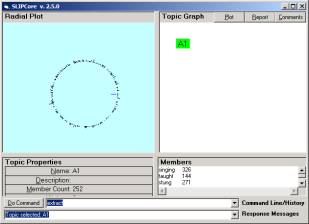
a b
Figure 5: The Technology Browser
To create the knowledge base one may issue the commands import and extract. Import reacquires the in memory data structure produced by the Warehouse browser. Extract conducts a data aggregation process, invented by Prueitt (1996) and published as public domain in September 2001.
Extract produces a set of abstractions called SLIP atoms. In Figure 5b one sees that in our data set there are exactly 252 SLIP atoms.
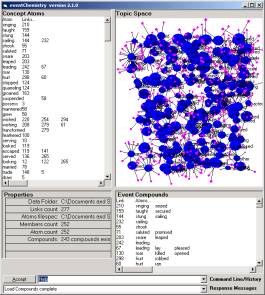
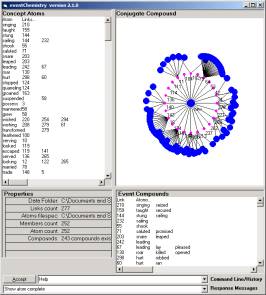
a b
Figure 6: The eventChemistry for category A1 (a) and the SLIP atom “saw’ (b)
Figure 6a shows the random scatter of the 252 atoms into an abstract object space.