the Orb for a cyber attack .
Stochastic and Fractal
Theory, an Outline for Future Work
January 30, 2002
Outline
- In this paper on eventChemistry we make the claim that the stochastic methods used in eventChemistry are fractal in nature! The claim is an important one, and we have some ideas on why the claim might be justified, and how one might explore this, were the claim to be shown to be true. These ideas include formal extensions of some existing work in computer science, logic and the foundations of mathematics.
- This is a deep result that is being developed as part of the logio-mathematical foundations to eventChemistry. The application of stochastic theory in eventChemistry plays the critical role of assigning meaning to multiple atoms when seen in proximity (by link analysis) to each other. This role, for stochastic theories, is close to the physical phenomenon of emergence. The formative process for events, leads to a specific chemistry based on the aggregation of substructural elements into a whole whose function is partially determined by the set of affordances present as the event forms. The environment anticipates the event.
- We hold that the experience of knowledge by a human must involve an interpretation process. Cognitive neuroscience suggests that the experience of knowledge involves a number of emergent phenomena such as electromagnetic phase coherence in the limbic system (following the results from Karl Pribram and others). Thus the role of the human, in our anticipatory technology, is to guide a specific stochastic process (using the notion of state/gesturing) via a software interface to an Event Information Base. The humans must also develop targeted research on the various compounds that are found to be of interest. An Event Information Base needs to be created to store and manage this research.
- The notion of residue and resonance also has a logio-mathematical foundation. Residue and resonance is both part of my unpublished work and part of the dialog I had with Russian semioticians and logicians (1995 – 1999). This work appears in various areas of mathematics and the mathematics of physics, but can be extended in a new way to information theory. [1]
- The OSI Browsers [2] can be used to by-pass a perceived scalability problem, This by-pass is relevant to a complete solution to our collective need to map ALL event types in the Internet that are of a threatening nature. By “by-pass” we mean the elimination of a hard problem by changing the framework in which the problem is stated. My favorite example of by-pass is writing the number 1/3 into a rational expansion. In base 10 this is not a task that can be completed in finite time. 1/3 = 0/3333 . . . . But in base 6, we find that 1/3 = 0.2. This is a by-pass, since the problem simply goes away. The use of number base conversations is actually used in our technical solutions.
- If used properly, ANY data set can be studied, split, and the focus shifted so that all data invariance is computed automatically and expressed in the form of a SLIP Framework. By split, I mean taking every nth record so that 1/n of the original data is selected. By focus, I mean finding the time when the first data about the event is present and the time when the last data about the event is present. An innovative method in data visualization and elementary number theory is available for shifting focus and selecting proper splittings.
· Once the beginning and ending times are identified, the selective focus can be used to extract relevant data from new data sets. This extraction process is a simple data mining process. However, the means to identify the beginning and end of events, where only partial and misleading information exists, is the hard problem we proposed to have solved.
The Preliminary Evidence
In Figure 1 we have the limiting distribution discussed in a recent paper on eventChemistry. One can compare this limiting distribution with Figure 2 and Figure 4. We note that a stochastic limiting distribution will be different each time it is computed, because there is randomness in the process of producing the limiting distribution. However, for a single data set, each limiting distribution is very similar to any other limiting distribution. One can directly see this for one’s self by using any of the free tutorials (that comes with downloadable software). These limiting distributions are mapping the functional load as defined in comparison with a concept in theoretical linguistics. Something about the relationship between the Nash equilibrium theorem and stratified complexity can be said here.
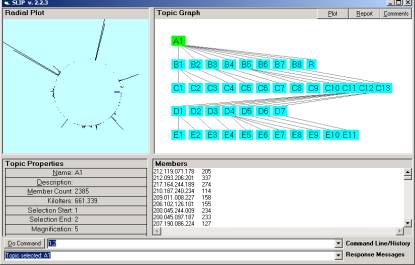
Figure 1: One of the m/9, where m < 9, limiting distributions
In Figure 2 we have a limiting distribution over a second splitting of the original dataset. The original data set has 65,535 records. Each of these two splitting have 7,281 records. The most critical point to recognize is that we change the starting position and then take every 9th record and place this record into a new file to form the two splitting. Thus the two data sets are physically “split”. No two data sets have a single record in the intersection.
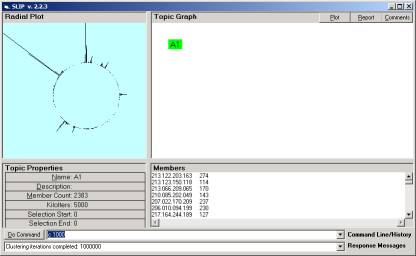
Figure 2: A second of the m/9, where m < 9, limiting distributions
There is a great deal of work that can be done here to formally exposit the evidence that the limiting distributions of splittings are a fractal type (holonomic) representation of the entire original data set. The first thing to notice is that the positioning of the clusters will vary as well the immediate surroundings of the clusters. We saw this in the early papers on SLIP distributions. However, the prime decomposition of these clusters will possibly produce a unique SLIP Framework. We have an ergodic conjecture regarding the invariance of a unique prime decomposition under certain types of splittings. This is an unproven conjecture at this time. Each Framework will produce almost exactly the same results.
SLIP Frameworks can be completely generated by an automated process. Early in the development of the first software, we approached the issue of Framework generation using a program that would cluster and then identify clusters of various types. Each cluster would be brought into a category and this category’s atom would be re-clustered to produce smaller clusters. A halting condition was defined and the notion of a unique decomposition of a set of atoms into primes was developed. Some of the early results where quite surprising.
Proof of Concept
In our previous paper we develop a complete SLIP Framework and then selected one of the small primes. A prime is a category with a linkage relationship that will bring the elements of the prime to the same location during the stochastic process of scatter gather. The data used is a 1/9 splitting of the original data. The event compound for this small prime is Figure 3a. We then took a 1/50 splitting of the original data (Figure 4).
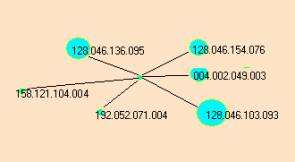
a b
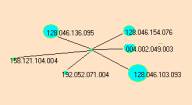
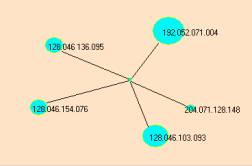
Figure 3: Two similar event compounds involving port 123.
The atoms { 128.046.136.095, 128.046.154.076, 128.046.103.093, 192,052.071.004 } are common to both event maps. Both event maps are linked together by the Destination Port 123.
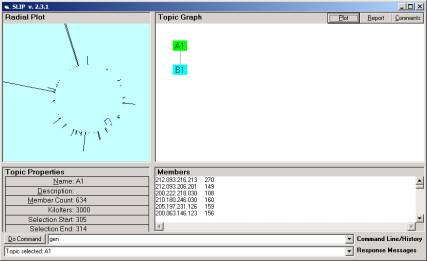
Figure 4: One of the m/50, where m < 50, limiting distributions
In Figure 4 we identified one of the atoms from Figure 3a to be part of a small category (marked by the blue bracket in Figure 4). On closer inspection we found the cluster had the five atoms shown in Figure 3b.
The point of this is that an event found using 1/9 the data is almost completely found using only 1/50th of the data. We would also find this same event in any of the other 1/9 splittings. Why? Well the answer is that we are creating levels of abstraction. By this we point out that the counting numbers are abstractions, as are the concepts of the atoms in the periodic table. We commonly use abstractions all of the time.
In Figure 4, we see the large spike at about 100 degrees, and a second large spike at around 170 degrees. By looking in Figure 1 and Figure 2 one see similar structures. One of the differences between the 1/9 distributions and the 1/50th distribution is the degree to which small groups break away from each other. This is perhaps expected, as the background noise is reduced where as the primary patterns are seen because sufficient data still exists to produce the abstractions. We will loose many of the small events. However the larger events will be more clearly seen.
Consequences Outline
· One can sample the Internet transactions from say 2% of the Intrusion Detection Systems to produce a low resolution picture of the entire set of transactions
· One can use Honey-Nets to bring certain intrusions into a safe place to study and monitor for the purpose of identifying who is involved in causing the intrusions.
· One can create profiles of threatening individuals and organizations so that these profiles can be used in predictive analysis and open legal actions.
· One can reduce the volume of intrusion activity by radically increasing the probability of detection and identification of the source of new virus and hacker tools.
· One can map out other illegal activities that depend on the dark alley that the Internet has become.
· One can anticipate, predict and prepare for a Cyber War and diffuse entirely the potential for damage BEFORE the damage occurs.
A computational system can be rapidly created that provides Selective Attention to classes of Internet phenomenon. This system can be modeled after the perceptional system of the human brain, and thus have intrinsic beauty in and of itself, in addition to shining a light into the dark alleys of the World Wide Web.
This model, and the theory of stratified complexity, is derived from the work of a number of scholars.
Chantilly VA